

 Software in 2026")



")













")






 & How They Work")
Key Takeaways
- Understand the architecture: Dive deep into the transformative power of Large Language Models (LLMs) and unravel the intricacies of their underlying architecture.
- Explore training methodologies: Learn how LLMs are trained on massive datasets using self-supervised learning techniques, paving the way for unparalleled language understanding and generation.
- Unlock real-world applications: Discover how LLMs are reshaping industries and revolutionizing communication through applications like chatbots, virtual assistants, and automated content generation.
In an era where digital interactions dominate every facet of our lives, understanding the backbone of language processing technology has become paramount.
Large Language Models (LLMs) stand at the forefront of this technological revolution, wielding unprecedented power to comprehend, generate, and manipulate human language with remarkable finesse.
But what exactly are these enigmatic entities, and how do they wield such linguistic prowess?

Welcome to our deep dive into the realm of Large Language Models (LLMs) – a journey where we’ll unravel the mysteries surrounding these titans of natural language processing and explore the intricate mechanisms that propel their functionality.
Setting the Stage: The Rise of Large Language Models
As we embark on this exploration, it’s essential to grasp the profound impact LLMs have had on reshaping the landscape of artificial intelligence (AI) and revolutionizing the way machines interact with human language.
From facilitating more intuitive virtual assistants to powering cutting-edge language translation tools, LLMs have transcended mere technological advancements to become indispensable pillars of modern-day innovation.
The Quest for Understanding: Defining Large Language Models
Before we delve deeper into the inner workings of LLMs, let’s establish a foundational understanding of what sets them apart from conventional language models.
At their core, LLMs are massive neural networks trained on vast corpora of text data, honed to comprehend and generate human-like language patterns with astonishing accuracy and fluency.
Unlike their predecessors, which often grappled with semantic nuances and contextuality, LLMs excel in capturing the intricacies of language with unprecedented fidelity, thanks to their sheer scale and sophisticated architectures.
Decoding the Architecture: Unveiling the Components of LLMs
To comprehend how LLMs operate their linguistic wizardry, it’s essential to dissect the intricate layers of their architecture.
From the input layer, where raw text data is ingested, to the transformative layers of attention mechanisms and the output layer where coherent language emerges, each component plays a pivotal role in shaping the LLM’s ability to understand and generate human-like text.
The Journey of Mastery: Training Large Language Models
Behind every LLM’s remarkable linguistic prowess lies a rigorous training regimen fueled by vast swathes of text data and sophisticated machine learning algorithms.
Through a combination of supervised and self-supervised learning techniques, LLMs undergo iterative training cycles, fine-tuning their parameters and honing their linguistic intuition until they achieve unprecedented levels of proficiency in understanding and generating human language.
The Alchemy of Text Generation: Unraveling LLMs’ Textual Sorcery
At the heart of every LLM lies the transformative process of text generation – a feat that seamlessly melds linguistic intuition with computational prowess.
By harnessing the power of attention mechanisms and contextual embeddings, LLMs traverse the vast expanse of language space, weaving together coherent sentences and narratives that rival those crafted by human hands.
As we embark on this odyssey through the realm of Large Language Models (LLMs), prepare to witness the convergence of cutting-edge technology and linguistic finesse as we unravel the mysteries behind these titans of natural language processing.
Join us as we journey deeper into the labyrinth of LLMs, where each discovery brings us closer to unlocking the secrets of human language itself.
Before we venture further into this article, we like to share who we are and what we do.
About 9cv9
9cv9 is a business tech startup based in Singapore and Asia, with a strong presence all over the world.
With over eight years of startup and business experience, and being highly involved in connecting with thousands of companies and startups, the 9cv9 team has listed some important learning points in this overview of What are Large Language Models (LLMs) & How They Work.
If your company needs recruitment and headhunting services to hire top-quality employees, you can use 9cv9 headhunting and recruitment services to hire top talents and candidates. Find out more here, or send over an email to [email protected].
Or just post 1 free job posting here at 9cv9 Hiring Portal in under 10 minutes.
What are Large Language Models (LLMs) & How They Work
- Understanding Large Language Models (LLMs)
- The Architecture of Large Language Models
- Training Large Language Models
- How Large Language Models Generate Text
- Applications of Large Language Models
- Ethical and Societal Implications
- Future Trends and Developments in LLMs
1. Understanding Large Language Models (LLMs)
In this section, we’ll delve into the fundamental concepts behind Large Language Models (LLMs), exploring their defining characteristics, key functionalities, and real-world applications.
By grasping the intricacies of LLMs, we can gain deeper insights into their transformative potential across various domains.

Defining Large Language Models (LLMs)
- Scale and Scope: LLMs are characterized by their expansive size and capacity to process vast amounts of text data. Unlike traditional language models, LLMs leverage deep neural networks with millions or even billions of parameters, enabling them to capture intricate linguistic patterns and nuances.
- Natural Language Understanding: One of the primary functions of LLMs is to comprehend human language in its various forms, including text input in multiple languages, speech recognition, and sentiment analysis. By leveraging their massive datasets and complex architectures, LLMs can discern context, infer meaning, and generate coherent responses with remarkable accuracy.
- Examples: Prominent examples of LLMs include OpenAI’s GPT (Generative Pre-trained Transformer) models, such as GPT-3, which have garnered widespread acclaim for their ability to perform diverse language tasks, ranging from text completion and summarization to language translation and question answering.
Key Components of LLM Architecture
- Input Layer: At the core of every LLM lies the input layer, where raw text data is ingested and encoded into numerical representations. This initial preprocessing step lays the foundation for subsequent processing and analysis by the neural network.
- Transformer Layers: The transformative power of LLMs resides in their multi-layered architecture, featuring stacks of transformer layers that enable hierarchical processing of input data. These transformer layers employ self-attention mechanisms to prioritize relevant information and capture long-range dependencies within the text.
- Output Layer: As the final stage of processing, the output layer of an LLM synthesizes the accumulated information from the preceding layers to generate coherent text outputs. Whether completing a sentence, answering a query, or generating creative prose, the output layer plays a crucial role in shaping the LLM’s linguistic output.
Exploring LLM Functionality
- Text Generation: One of the hallmark capabilities of LLMs is their ability to generate human-like text based on input prompts or contextual cues. By leveraging learned language patterns and contextual embeddings, LLMs can produce coherent and contextually relevant responses across a wide range of topics and styles.
- Language Understanding: Beyond mere text generation, LLMs excel in understanding and contextualizing human language input. Whether parsing complex syntax, disambiguating ambiguous terms, or discerning sentiment and tone, LLMs demonstrate a remarkable aptitude for comprehending the subtleties of human communication.
- Real-time Interaction: LLMs are increasingly being integrated into interactive applications and platforms, enabling real-time communication between humans and machines. From chatbots and virtual assistants to language translation services and content generation tools, LLMs are driving innovation in user interfaces and natural language interfaces.
Real-World Applications of LLMs
- Virtual Assistants: Companies like Google, Amazon, and Apple are leveraging LLMs to power their virtual assistant platforms, enabling users to interact with smart devices using natural language commands and queries.
- Content Generation: LLMs are revolutionizing content creation and automation across various industries, from journalism and marketing to e-commerce and entertainment. By generating personalized recommendations, product descriptions, and marketing copy, LLMs are streamlining content workflows and enhancing user engagement.
- Language Translation: LLMs have also made significant strides in the field of language translation, enabling near-instantaneous conversion of text between different languages with remarkable accuracy and fluency. Platforms like Google Translate and DeepL rely on LLMs to provide seamless cross-lingual communication for users worldwide.
Summary
In summary, understanding the intricacies of Large Language Models (LLMs) is essential for unlocking their transformative potential in various domains.
By grasping the underlying principles of LLM architecture, functionality, and real-world applications, we can harness the power of these cutting-edge technologies to drive innovation, enhance communication, and shape the future of human-machine interaction.
2. The Architecture of Large Language Models
In this section, we’ll delve into the intricate architecture that underpins Large Language Models (LLMs), exploring the key components and mechanisms that enable these models to process and generate human-like text at scale.
Understanding the architecture of LLMs is essential for unraveling their inner workings and appreciating their transformative potential in natural language processing tasks.
Components of LLM Architecture
- Input Layer:
- The entry point of the LLM, where raw text data is ingested and encoded into numerical representations.
- Utilizes techniques such as tokenization and embedding to convert textual input into a format suitable for neural network processing.
- Example: In OpenAI’s GPT-3 model, the input layer processes tokenized text sequences, encoding each token into a high-dimensional vector representation.
- Transformer Layers:
- The backbone of LLM architecture, comprising multiple stacked transformer layers that enable hierarchical processing of input data.
- Each transformer layer consists of self-attention mechanisms, feedforward neural networks, and layer normalization operations.
- Example: The BERT (Bidirectional Encoder Representations from Transformers) model utilizes transformer layers to capture bidirectional contextual information within input sequences, enabling more accurate language understanding.
- Output Layer:
- The final stage of processing in the LLM, where accumulated information from transformer layers is synthesized to generate text outputs.
- Typically involves a softmax layer for probability distribution over vocabulary tokens, enabling the model to predict the next word in a sequence.
- Example: In text generation tasks, the output layer of an LLM generates a probability distribution over vocabulary tokens, allowing the model to select the most likely next word based on learned language patterns.
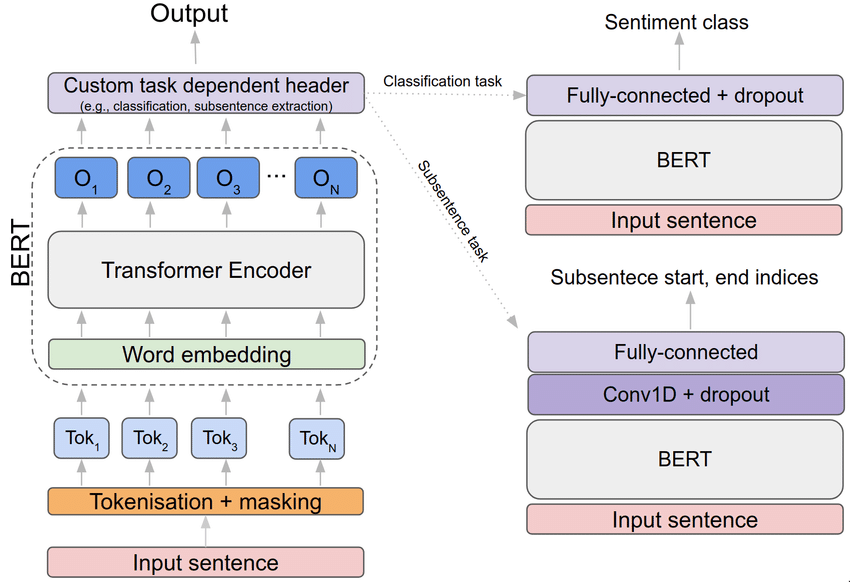
Mechanisms of LLM Architecture
- Self-Attention Mechanisms:
- Central to the functioning of transformer layers, self-attention mechanisms enable LLMs to prioritize relevant information within input sequences.
- Allows the model to capture long-range dependencies and contextual relationships between words in a sentence.
- Example: In the transformer architecture, self-attention mechanisms compute attention scores for each word in a sequence, allowing the model to focus on informative tokens while processing input data.
- Feedforward Neural Networks (FFNN):
- Found within each transformer layer, feedforward neural networks process information from self-attention mechanisms to generate intermediate representations.
- Typically consist of multiple layers of densely connected neurons, with activation functions applied to compute nonlinear transformations.
- Example: In BERT-based models, feedforward neural networks transform contextualized word embeddings generated by self-attention mechanisms into higher-level representations suitable for downstream tasks such as text classification or named entity recognition.
- Layer Normalization:
- Ensures stable training and convergence of LLMs by normalizing the activations within each layer of the transformer architecture.
- Reduces the impact of covariate shift and internal covariate shift, leading to more robust and efficient training.
- Example: Layer normalization is applied after each sub-layer within transformer layers, ensuring consistent distribution of activations and facilitating smoother gradient flow during backpropagation.
Scalability and Efficiency in LLM Architecture
- Parameterization:
- LLMs are characterized by their massive scale, with millions or even billions of parameters that govern model behavior.
- The sheer number of parameters enables LLMs to capture intricate language patterns and nuances, leading to improved performance on diverse language tasks.
- Example: OpenAI’s GPT-3 model consists of 175 billion parameters, making it one of the largest and most powerful LLMs to date.
- Parallelism:
- LLM architectures are designed to leverage parallel computing resources, enabling efficient training and inference on large-scale datasets.
- Parallel processing techniques such as data parallelism and model parallelism are employed to distribute computational workload across multiple GPUs or TPUs.
- Example: Distributed training frameworks like TensorFlow and PyTorch enable researchers to train LLMs across clusters of GPUs or TPUs, accelerating the training process and reducing time-to-deployment.
Real-World Examples of LLM Architecture
- GPT-3 (Generative Pre-trained Transformer 3):
- OpenAI’s GPT-3 model exemplifies the transformer-based architecture, featuring multiple transformer layers with scaled self-attention mechanisms.
- With 175 billion parameters, GPT-3 achieves state-of-the-art performance on a wide range of natural language processing tasks, including text generation, language translation, and question answering.
- Example: GPT-3 powers applications such as chatbots, language translation services, and content generation tools, demonstrating the versatility and efficacy of transformer-based LLMs in real-world scenarios.
- BERT (Bidirectional Encoder Representations from Transformers):
- Developed by Google AI, BERT revolutionized natural language understanding with its bidirectional transformer architecture.
- BERT’s architecture consists of transformer layers pre-trained on large-scale text corpora, followed by fine-tuning on task-specific datasets for downstream applications.
- Example: BERT has been widely adopted in applications such as sentiment analysis, named entity recognition, and semantic search, demonstrating its effectiveness in capturing bidirectional contextual information within text sequences.
Summary
The architecture of Large Language Models (LLMs) represents a fusion of cutting-edge techniques in deep learning, natural language processing, and parallel computing.
By leveraging transformer-based architectures with self-attention mechanisms, feedforward neural networks, and layer normalization, LLMs achieve remarkable scalability, efficiency, and performance across diverse language tasks.
Real-world examples such as GPT-3 and BERT showcase the transformative potential of LLM architecture in powering innovative applications and driving advancements in natural language understanding and generation.
As LLMs continue to evolve and scale, their architecture will remain a cornerstone of progress in the field of artificial intelligence and human-machine interaction.
3. Training Large Language Models
In this section, we’ll explore the intricate process of training Large Language Models (LLMs), shedding light on the methodologies, challenges, and innovations that drive the evolution of these cutting-edge AI systems.
From data collection and preprocessing to the deployment of advanced training techniques, understanding the training process is essential for unlocking the full potential of LLMs in natural language processing tasks.
Data Collection and Preprocessing
- Corpus Selection:
- The first step in training an LLM involves selecting a diverse and representative corpus of text data from various sources, such as books, articles, websites, and social media.
- The quality, size, and diversity of the training data play a crucial role in shaping the performance and generalization capabilities of the LLM.
- Example: OpenAI’s GPT-3 model was trained on a vast corpus of internet text comprising billions of words, spanning multiple languages and domains.
- Text Preprocessing:
- Raw text data undergoes preprocessing steps such as tokenization, lowercasing, punctuation removal, and special character handling to prepare it for input into the neural network.
- Techniques like subword tokenization and byte pair encoding (BPE) are employed to handle out-of-vocabulary words and improve the model’s vocabulary coverage.
- Example: In the BERT model, text preprocessing involves tokenizing input sequences into subword tokens using the WordPiece algorithm, followed by adding special tokens for classification tasks.
Training Process
- Supervised Learning:
- In supervised learning, LLMs are trained on labeled datasets where each input sequence is associated with a corresponding target output, such as sentiment labels or named entity annotations.
- The model learns to minimize a predefined loss function by adjusting its parameters through backpropagation, optimizing performance on the given task.
- Example: BERT-based models are often fine-tuned on task-specific datasets for tasks like text classification, sequence labeling, and question answering, achieving state-of-the-art performance with minimal labeled data.
- Self-Supervised Learning:
- Self-supervised learning techniques involve training LLMs on unlabeled text data, where the model predicts masked or corrupted tokens within input sequences.
- By leveraging contextual clues and linguistic patterns within the data, LLMs learn to reconstruct the original text, effectively capturing latent semantic representations.
- Example: OpenAI’s GPT models are pre-trained using a self-supervised learning objective known as masked language modeling (MLM), where the model predicts masked tokens within input sequences based on surrounding context.
Challenges and Considerations
- Data Bias and Quality:
- Training LLMs on biased or low-quality data can lead to model performance degradation and reinforce existing societal biases present in the training data.
- Mitigating data bias requires careful curation of training datasets, robust data augmentation techniques, and rigorous evaluation of model outputs for fairness and inclusivity.
- Example: Researchers have developed techniques such as adversarial training and data augmentation to address biases in LLMs and promote more equitable language generation.
- Computational Resources:
- Training large-scale LLMs requires substantial computational resources, including high-performance GPUs, TPUs, and distributed computing infrastructure.
- The cost and energy consumption associated with training LLMs at scale pose challenges in terms of accessibility, environmental sustainability, and economic feasibility.
- Example: Companies like OpenAI and Google have invested significant resources in developing specialized hardware accelerators and distributed training frameworks to train LLMs efficiently and cost-effectively.
Innovations in LLM Training
- Multi-Task Learning:
- Multi-task learning enables LLMs to simultaneously train on multiple related tasks, leveraging shared representations and improving overall performance and generalization.
- By jointly optimizing across diverse language tasks, LLMs can learn robust and transferable features that capture a wide range of linguistic phenomena.
- Example: The T5 (Text-To-Text Transfer Transformer) model by Google AI is trained using a unified text-to-text framework, where diverse language tasks are cast as text generation tasks, enabling seamless multi-task learning.
- Continual Learning:
- Continual learning techniques enable LLMs to adapt and learn incrementally from new data over time, without catastrophic forgetting of previously acquired knowledge.
- By retaining knowledge from past experiences while accommodating new information, LLMs can maintain relevance and adaptability in dynamic environments.
- Example: Research in continual learning for LLMs has led to advancements in techniques such as parameter regularization, rehearsal strategies, and episodic memory mechanisms, enabling lifelong learning capabilities.
Real-World Impact and Applications
- Language Understanding and Generation:
- Well-trained LLMs demonstrate superior performance in various natural language understanding and generation tasks, including language translation, sentiment analysis, summarization, and dialogue generation.
- By leveraging contextual embeddings and learned language patterns, LLMs empower applications such as virtual assistants, chatbots, content generation tools, and language translation services.
- Example: Google’s BERT model has been integrated into search algorithms to improve the relevance and accuracy of search results by better understanding user queries and context.
- Scientific Research and Innovation:
- LLMs serve as powerful tools for accelerating scientific research and innovation across diverse domains, including healthcare, finance, education, and environmental science.
- Researchers leverage pre-trained LLMs for tasks such as drug discovery, protein folding prediction, financial forecasting, educational content generation, and climate modeling, driving advancements in knowledge discovery and decision-making.
- Example: The COVID-19 pandemic prompted researchers to use LLMs for analyzing biomedical literature, identifying potential drug candidates, and generating insights into virus transmission dynamics, contributing to global efforts in combating the pandemic.
Summary
The training of Large Language Models (LLMs) represents a complex and iterative process that involves data collection, preprocessing, model training, and evaluation.
By leveraging supervised and self-supervised learning techniques, researchers can train LLMs to excel in diverse natural language processing tasks, driving innovations in communication, information retrieval, scientific discovery, and societal impact.
Despite challenges such as data bias and computational resource requirements, ongoing advancements in LLM training methodologies and applications hold promise for unlocking new frontiers in AI and shaping the future of human-machine interaction.
4. How Large Language Models Generate Text
In this section, we’ll explore the fascinating process by which Large Language Models (LLMs) generate human-like text, unraveling the underlying mechanisms and techniques that enable these models to produce coherent and contextually relevant outputs.
From understanding the role of attention mechanisms to examining the nuances of text generation, delving into the intricacies of LLMs’ text generation capabilities is essential for grasping their transformative potential in natural language processing tasks.
Mechanics of Text Generation in LLMs
- Contextual Embeddings:
- LLMs leverage contextual embeddings to encode input sequences into high-dimensional vector representations that capture semantic and syntactic information.
- Contextual embeddings enable the model to understand the context of a given input and generate text outputs that are contextually relevant.
- Example: In OpenAI’s GPT-3 model, each word token is embedded into a dense vector representation based on its surrounding context, allowing the model to capture nuanced semantic relationships within the text.
- Attention Mechanisms:
- Attention mechanisms play a crucial role in guiding the text generation process by allowing the model to focus on relevant parts of the input sequence.
- By assigning attention weights to different tokens in the input, LLMs prioritize important information and incorporate it into the generated output.
- Example: Transformers, the architecture underlying many LLMs, utilize self-attention mechanisms to compute attention scores for each word token, enabling the model to attend to relevant context when generating text.
Role of Context and Conditioning
- Contextual Prompts:
- LLMs often generate text based on contextual prompts provided by the user, which serve as starting points or cues for the model to continue generating coherent text.
- The quality and specificity of the prompt influence the generated output, as the model uses the provided context to guide its language generation process.
- Example: When prompted with the phrase “Once upon a time,” an LLM might generate a story beginning, leveraging its learned language patterns and storytelling conventions.
- Conditioning on Input:
- LLMs condition their text generation process on the entire input sequence, incorporating information from preceding tokens to generate subsequent ones.
- This conditioning allows the model to maintain coherence and consistency throughout the generated text, ensuring that each token aligns with the overall context.
- Example: In language translation tasks, an LLM conditions its text generation process on the source language input, producing a translated output that preserves the semantic meaning and syntactic structure of the original text.
Generating Coherent Text Outputs
- Sampling Strategies:
- LLMs employ various sampling strategies to generate text outputs, ranging from deterministic methods like greedy decoding to stochastic approaches like beam search and sampling.
- These strategies influence the diversity, fluency, and novelty of the generated text, balancing between generating coherent outputs and exploring alternative language possibilities.
- Example: Beam search, a commonly used decoding algorithm, explores multiple candidate sequences during text generation, selecting the most probable continuation based on a predefined beam width.
- Temperature Scaling:
- Temperature scaling is a technique used to control the diversity of text generated by LLMs by scaling the logits (log-odds) of the softmax distribution during sampling.
- Lower temperatures result in more deterministic outputs, while higher temperatures lead to more diverse and exploratory outputs.
- Example: By adjusting the temperature parameter during text generation, users can fine-tune the balance between generating conservative, high-confidence responses and exploring more creative, low-confidence responses.
Real-World Examples of Text Generation
- Chatbots and Virtual Assistants:
- LLMs power chatbots and virtual assistants that engage in natural language conversations with users, providing information, answering questions, and performing tasks.
- These applications leverage LLMs’ text generation capabilities to produce contextually relevant responses that simulate human-like interactions.
- Example: Google’s Meena and Amazon’s Alexa are virtual assistants that use LLMs to understand user queries and generate appropriate responses, demonstrating the versatility and effectiveness of LLM-based conversational agents.
- Content Generation Tools:
- LLMs are utilized in content generation tools that automate the creation of text-based content such as articles, product descriptions, and marketing copy.
- These tools leverage LLMs’ ability to generate coherent and persuasive text tailored to specific topics and audiences.
- Example: Copywriting platforms like Copy.ai and Writesonic use LLMs to generate website copy, social media posts, and ad headlines, enabling businesses to streamline content creation processes and enhance marketing campaigns.
Ethical and Societal Implications
- Bias and Fairness:
- LLMs can perpetuate or amplify biases present in the training data, leading to biased or discriminatory outputs.
- Addressing bias and promoting fairness in LLM-generated text requires careful data curation, algorithmic transparency, and ongoing evaluation and mitigation efforts.
- Example: Researchers have developed bias detection techniques and debiasing algorithms to identify and mitigate biases in LLM-generated text, ensuring fair and inclusive language generation.
- Misinformation and Manipulation:
- LLMs have the potential to generate misleading or harmful content, including misinformation, propaganda, and hate speech.
- Safeguarding against misinformation and manipulation involves implementing content moderation measures, fact-checking mechanisms, and user education initiatives.
- Example: Social media platforms employ algorithms and human moderators to detect and remove harmful content generated by LLMs, mitigating the spread of misinformation and protecting user trust and safety.
Summary
The text generation capabilities of Large Language Models (LLMs) represent a remarkable feat of artificial intelligence, enabling these models to produce coherent and contextually relevant outputs across a wide range of natural language tasks.
By leveraging contextual embeddings, attention mechanisms, and sampling strategies, LLMs generate text that simulates human-like communication, powering applications such as chatbots, virtual assistants, and content generation tools.
However, the ethical and societal implications of LLM-generated text, including bias, misinformation, and manipulation, underscore the importance of responsible development, deployment, and oversight of LLM technologies.
As LLMs continue to evolve and proliferate, addressing these challenges will be essential for harnessing the full potential of these powerful AI systems while ensuring their responsible and ethical use in society.
5. Applications of Large Language Models
Large Language Models (LLMs) have revolutionized various industries and domains with their remarkable ability to understand, generate, and manipulate human language.
In this section, we’ll explore the diverse range of applications where LLMs are making a significant impact, from enhancing communication and productivity to driving innovation and discovery.
Natural Language Understanding Tasks
- Text Classification:
- LLMs excel in categorizing text documents into predefined classes or categories, facilitating tasks such as sentiment analysis, topic classification, and spam detection.
- Example: Google’s BERT model is widely used for sentiment analysis in social media monitoring tools, helping businesses gauge public sentiment towards their products or brands.
- Named Entity Recognition (NER):
- LLMs can identify and classify named entities such as persons, organizations, locations, and dates within unstructured text data, enabling tasks like information extraction and entity linking.
- Example: The SpaCy library, powered by LLMs, offers state-of-the-art NER capabilities for extracting structured information from text documents in domains like healthcare and finance.
- Question Answering (QA):
- LLMs are adept at answering natural language questions by extracting relevant information from large text corpora and providing concise and accurate responses.
- Example: OpenAI’s GPT-3 model powers chatbots like ChatGPT, which can answer user queries on a wide range of topics with human-like understanding and fluency.
Text Generation Applications
- Content Creation:
- LLMs enable automated content creation across various formats, including articles, blog posts, product descriptions, and social media posts, by generating coherent and engaging text tailored to specific topics and audiences.
- Example: Tools like ShortlyAI and Copy.ai leverage LLMs to generate website content, marketing copy, and email newsletters, streamlining content creation workflows for businesses and marketers.
- Dialogue Systems:
- LLMs drive the development of conversational agents and chatbots that engage in natural language conversations with users, providing customer support, information retrieval, and entertainment services.
- Example: Microsoft’s XiaoIce is a popular chatbot in China that uses LLMs to converse with users on topics ranging from weather forecasts to emotional support, demonstrating the versatility and adaptability of LLM-based dialogue systems.
- Creative Writing:
- LLMs can assist writers and content creators in generating creative and compelling prose, poetry, and storytelling by providing inspiration, generating plot ideas, and suggesting stylistic improvements.
- Example: AI Dungeon, powered by OpenAI’s GPT-3 model, allows users to participate in interactive text-based adventures where the narrative is dynamically generated based on user input, showcasing the creativity and flexibility of LLM-generated content.
Industry-Specific Applications
- Healthcare:
- LLMs support various healthcare applications, including clinical documentation, medical transcription, patient communication, and automated diagnosis, by generating medical reports, summarizing patient data, and providing personalized health recommendations.
- Example: IBM’s Watson Health utilizes LLMs to analyze medical literature, interpret diagnostic images, and assist healthcare professionals in decision-making tasks such as treatment planning and drug discovery.
- Finance:
- LLMs play a vital role in financial analysis, risk assessment, fraud detection, and customer service in the banking, insurance, and investment sectors, by generating financial reports, analyzing market trends, and responding to customer inquiries.
- Example: Goldman Sachs’ AI-driven platform, Marcus Insights, leverages LLMs to analyze customer financial data and provide personalized insights and recommendations on saving, spending, and investing.
- Education:
- LLMs enhance educational experiences by providing personalized tutoring, automated grading, language learning support, and educational content generation, empowering learners and educators with adaptive and interactive learning tools.
- Example: Duolingo, a language learning platform, uses LLMs to generate personalized exercises, quizzes, and explanations tailored to individual learners’ proficiency levels and learning preferences, facilitating language acquisition and retention.
Ethical and Societal Implications
- Bias and Fairness:
- LLMs can perpetuate or amplify biases present in the training data, leading to biased or discriminatory outcomes in applications such as hiring, lending, and criminal justice.
- Addressing bias and promoting fairness in LLM applications requires ongoing efforts to diversify training data, mitigate algorithmic biases, and ensure transparency and accountability in decision-making processes.
- Privacy and Security:
- LLMs raise concerns about data privacy and security due to their ability to generate sensitive or personally identifiable information, posing risks to user privacy, confidentiality, and data protection.
- Safeguarding privacy and security in LLM applications entails implementing robust data anonymization techniques, encryption protocols, and access controls to protect sensitive information and mitigate privacy risks.
Summary
Large Language Models (LLMs) are transforming the way we communicate, collaborate, and innovate across diverse industries and domains.
By harnessing the power of natural language understanding and generation, LLMs enable a wide range of applications, from automating content creation and enhancing customer interactions to driving advancements in healthcare, finance, and education.
However, the ethical and societal implications of LLM adoption underscore the importance of responsible development, deployment, and governance to ensure equitable access, fairness, and privacy in the era of AI-driven language technologies.
As LLMs continue to evolve and proliferate, addressing these challenges will be essential for maximizing the benefits of LLM technologies while mitigating potential risks and ensuring their positive impact on society.
6. Ethical and Societal Implications
The widespread adoption of Large Language Models (LLMs) has sparked discussions about their ethical and societal implications, raising concerns about bias, privacy, security, and the broader impact of AI-driven language technologies.
In this section, we’ll delve into the multifaceted ethical considerations surrounding LLMs and explore strategies for addressing these challenges responsibly.
Bias and Fairness
- Algorithmic Bias:
- LLMs can perpetuate or amplify biases present in the training data, leading to biased or discriminatory outcomes in decision-making processes.
- Bias can manifest in various forms, including racial, gender, socioeconomic, and cultural biases, influencing AI-generated content, recommendations, and predictions.
- Example: Facial recognition systems trained on biased datasets have been shown to exhibit higher error rates for certain demographic groups, reinforcing existing societal biases and exacerbating disparities in AI applications.
- Fairness in AI:
- Ensuring fairness in LLMs requires addressing bias in training data, algorithms, and decision-making processes to mitigate adverse impacts on individuals or groups.
- Fairness metrics and evaluation frameworks are employed to assess and mitigate bias in AI systems, promoting equitable outcomes and mitigating harm.
- Example: Researchers have developed fairness-aware algorithms and debiasing techniques to mitigate bias in LLM-generated content and decision-making systems, promoting fairness and inclusivity in AI applications.
Privacy and Data Protection
- Data Privacy Risks:
- LLMs raise concerns about data privacy and security due to their access to vast amounts of sensitive and personally identifiable information.
- Privacy risks arise from the potential for unintended disclosure of confidential information, unauthorized access to personal data, and the misuse of AI-generated content for malicious purposes.
- Example: LLMs trained on social media data may inadvertently expose users’ private conversations, personal preferences, and sensitive information, posing risks to user privacy and confidentiality.
- Data Protection Regulations:
- Compliance with data protection regulations such as the General Data Protection Regulation (GDPR) and the California Consumer Privacy Act (CCPA) is essential for safeguarding user privacy in LLM applications.
- Adhering to privacy-by-design principles, obtaining informed consent, and implementing data anonymization techniques are critical for ensuring compliance and protecting user privacy.
- Example: Companies deploying LLM-based applications must adhere to data protection regulations, implement robust privacy policies, and provide users with transparent information about data collection, processing, and sharing practices.
Security and Misuse
- Security Risks:
- LLMs pose security risks such as adversarial attacks, data breaches, and manipulation of AI-generated content for malicious purposes.
- Adversarial attacks target vulnerabilities in LLMs’ decision boundaries, leading to misclassification, manipulation, or unauthorized access to sensitive information.
- Example: Adversarial examples crafted to deceive LLMs can lead to erroneous predictions, compromising the integrity and reliability of AI-driven decision-making systems in security-critical applications such as cybersecurity and fraud detection.
- Misuse and Manipulation:
- LLM-generated content can be manipulated or weaponized for misinformation, propaganda, hate speech, and other forms of online manipulation.
- Malicious actors exploit AI-generated content to spread disinformation, manipulate public opinion, and undermine trust in democratic institutions and social cohesion.
- Example: Deepfake videos generated by LLMs can be used to impersonate individuals, fabricate false narratives, and incite social unrest, highlighting the potential for AI-driven manipulation and deception in online platforms and media.
Accountability and Transparency
- Algorithmic Accountability:
- Establishing accountability mechanisms for LLMs involves clarifying roles and responsibilities, ensuring transparency in AI decision-making processes, and holding stakeholders accountable for the ethical and social impacts of their AI systems.
- Transparent AI governance frameworks, explainable AI techniques, and accountability mechanisms such as impact assessments and auditing are essential for promoting accountability and trust in LLM applications.
- Example: The European Union’s proposed Artificial Intelligence Act aims to establish a regulatory framework for AI systems, including LLMs, by ensuring transparency, accountability, and human oversight in their development and deployment.
- Ethical Guidelines and Standards:
- Ethical guidelines and standards provide principles and best practices for responsible AI development and deployment, guiding stakeholders in navigating ethical dilemmas and ensuring alignment with societal values and norms.
- Industry initiatives, professional associations, and governmental agencies develop ethical guidelines and standards to promote ethical AI practices and mitigate potential harms associated with LLMs.
- Example: The IEEE Global Initiative on Ethics of Autonomous and Intelligent Systems and the Partnership on AI (PAI) have developed ethical guidelines and principles for AI development, including recommendations for transparency, fairness, accountability, and societal impact assessment in LLM applications.
Summary
The ethical and societal implications of Large Language Models (LLMs) are multifaceted and complex, encompassing concerns about bias, privacy, security, accountability, and transparency.
Addressing these challenges requires a holistic approach that involves collaboration among stakeholders, including researchers, developers, policymakers, and civil society organizations.
By adopting ethical AI principles, promoting transparency and accountability, and prioritizing user privacy and societal well-being, we can harness the transformative potential of LLMs while mitigating potential risks and ensuring their responsible and ethical use in society.
7. Future Trends and Developments in LLMs
The field of Large Language Models (LLMs) is evolving rapidly, driven by advancements in artificial intelligence, natural language processing, and deep learning techniques.
In this section, we’ll explore the emerging trends and future developments shaping the landscape of LLM research and applications, from model architectures and training methodologies to ethical considerations and societal impacts.
Architectural Innovations
- Scalability and Efficiency:
- Future LLMs are expected to continue growing in scale, with even larger model sizes and higher parameter counts to capture more complex language patterns and nuances.
- Innovations in model compression, sparse attention mechanisms, and efficient inference techniques will be crucial for scaling LLMs to handle larger datasets and more computationally intensive tasks.
- Example: Research in sparse attention mechanisms, such as Longformer and BigBird, aims to improve the efficiency and scalability of LLMs by reducing the computational overhead of processing long sequences.
- Hybrid Architectures:
- Hybrid LLM architectures that combine the strengths of different model paradigms, such as transformers, recurrent neural networks (RNNs), and convolutional neural networks (CNNs), are expected to emerge, enabling more flexible and adaptable language processing capabilities.
- By integrating diverse architectural components, hybrid LLMs can leverage the complementary strengths of different model architectures to achieve superior performance on a wide range of language tasks.
- Example: The Transformer-XL model combines transformer architecture with recurrence mechanisms to capture long-range dependencies and context in sequential data, demonstrating the potential of hybrid LLM architectures for language understanding and generation.
Training Methodologies
- Self-Supervised Learning:
- Future LLMs will continue to leverage self-supervised learning techniques to pre-train models on large unlabeled datasets, enabling unsupervised feature learning and transfer learning across diverse language tasks.
- Advances in self-supervised learning objectives, such as contrastive learning and generative adversarial training, will improve the robustness and generalization capabilities of LLMs by exposing models to diverse training signals and data distributions.
- Example: Contrastive pre-training methods, such as SimCLR and SwAV, encourage LLMs to learn semantically meaningful representations by contrasting positive and negative samples in high-dimensional embedding spaces, leading to improved downstream performance on language tasks.
- Continual Learning:
- Continual learning techniques will play a crucial role in enabling LLMs to adapt and learn from new data over time, without catastrophic forgetting of previously acquired knowledge.
- Research in continual learning algorithms, regularization techniques, and memory-augmented architectures will enhance the lifelong learning capabilities of LLMs, enabling them to retain and adapt knowledge across diverse domains and contexts.
- Example: Elastic Weight Consolidation (EWC) and Online EWC are continual learning techniques that prioritize important parameters in LLMs and constrain their plasticity to prevent catastrophic forgetting, facilitating continual learning in dynamic environments.
Ethical and Societal Considerations
- Fairness and Bias Mitigation:
- Addressing bias and promoting fairness in LLMs will remain a critical area of focus, with efforts to develop bias detection methods, debiasing techniques, and fairness-aware algorithms to mitigate algorithmic biases and promote equitable outcomes.
- Collaborative initiatives between researchers, industry stakeholders, and policymakers will be essential for developing standardized evaluation metrics, guidelines, and regulatory frameworks to ensure fairness and accountability in LLM applications.
- Example: The development of fairness-aware AI frameworks, such as Fairness Indicators and AI Fairness 360, enables stakeholders to assess and mitigate bias in LLM-generated content and decision-making systems, promoting fairness and inclusivity in AI applications.
- Privacy-Preserving Technologies:
- Privacy-preserving technologies and cryptographic techniques will play an increasingly important role in safeguarding user privacy and confidentiality in LLM applications, particularly in domains such as healthcare, finance, and personal communication.
- Innovations in federated learning, differential privacy, and secure multi-party computation will enable collaborative training of LLMs on decentralized data sources while preserving the privacy of individual users.
- Example: Federated learning frameworks, such as TensorFlow Federated and PySyft, enable LLMs to be trained on distributed data sources without sharing raw data, preserving user privacy and data sovereignty in decentralized learning environments.
Real-World Applications
- Multimodal LLMs:
- Future LLMs will integrate multimodal capabilities to process and generate text in conjunction with other modalities such as images, audio, and video, enabling more immersive and contextually rich language understanding and generation.
- Multimodal LLMs will enable applications such as image captioning, visual question answering, and multimodal dialogue systems, facilitating more natural and expressive human-machine interactions.
- Example: OpenAI’s CLIP model demonstrates the potential of multimodal LLMs by learning to associate textual descriptions with images across diverse domains, enabling zero-shot image classification and retrieval.
- Personalized and Adaptive LLMs:
- Personalized LLMs that adapt to individual user preferences, language styles, and contexts will become increasingly prevalent, enabling more tailored and user-centric language generation experiences.
- Advances in reinforcement learning, meta-learning, and contextual adaptation techniques will enable LLMs to dynamically adjust their language generation strategies based on user feedback, environmental cues, and task requirements.
- Example: Personalized language models, such as ChatGPT with user-specific fine-tuning, can adapt to individual users’ conversational styles, preferences, and interests, enhancing the relevance and engagement of AI-generated content.
Summary
The future of Large Language Models (LLMs) holds immense promise for advancing the state-of-the-art in natural language processing, enabling more powerful, versatile, and responsible AI-driven language technologies.
By embracing architectural innovations, training methodologies, and ethical considerations, researchers and developers can harness the transformative potential of LLMs to address complex societal challenges, enhance human-machine collaboration, and empower users with more intuitive and personalized language experiences.
As LLMs continue to evolve and proliferate, interdisciplinary collaboration and stakeholder engagement will be crucial for shaping the future trajectory of LLM research and applications, ensuring their positive impact on society and human well-being.
Conclusion
Large Language Models (LLMs) represent a groundbreaking advancement in the field of artificial intelligence, revolutionizing the way we interact with and understand natural language.
Throughout this blog, we’ve explored the intricacies of LLMs, from their underlying architecture and training methodologies to their diverse applications and ethical considerations.
LLMs, such as OpenAI’s GPT series and Google’s BERT, are built upon transformer architecture, leveraging self-attention mechanisms to capture contextual dependencies and generate coherent and contextually relevant text.
These models undergo extensive pre-training on large corpora of text data using self-supervised learning techniques, enabling them to learn rich semantic representations and linguistic patterns from unlabeled data.
Fine-tuning on task-specific datasets further enhances the performance of LLMs across various natural language processing tasks, including text classification, sentiment analysis, question answering, and language translation.
The applications of LLMs are vast and far-reaching, spanning industries such as healthcare, finance, education, and entertainment.
These models power chatbots, virtual assistants, content generation tools, and language understanding systems, facilitating human-machine interaction and driving innovation in communication, productivity, and decision-making.
However, the widespread adoption of LLMs also raises important ethical and societal considerations, including concerns about bias, privacy, security, and the responsible use of AI technologies.
Looking ahead, the future of LLMs holds tremendous promise for further advancements and developments.
Architectural innovations, such as hybrid architectures and multimodal LLMs, will enable more versatile and adaptable language processing capabilities, while training methodologies like continual learning and personalized adaptation will enhance the lifelong learning and user-centricity of LLMs.
Ethical considerations, including fairness, transparency, and privacy preservation, will remain paramount in ensuring the responsible development and deployment of LLMs in society.
In essence, Large Language Models are not just powerful AI systems; they are transformative agents that have the potential to shape the future of human-machine interaction, communication, and knowledge dissemination.
By understanding how LLMs work and embracing their capabilities and limitations, we can harness the full potential of these remarkable technologies to address complex challenges, empower individuals, and build a more inclusive and equitable future for all.
If your company needs HR, hiring, or corporate services, you can use 9cv9 hiring and recruitment services. Book a consultation slot here, or send over an email to [email protected].
If you find this article useful, why not share it with your hiring manager and C-level suite friends and also leave a nice comment below?
We, at the 9cv9 Research Team, strive to bring the latest and most meaningful data, guides, and statistics to your doorstep.
To get access to top-quality guides, click over to 9cv9 Blog.
People Also Ask
What are Large Language Models (LLMs) and why are they important?
LLMs are AI models capable of understanding and generating human-like text. They’re crucial for various tasks, from chatbots to content generation, due to their advanced language processing abilities.
How do Large Language Models work?
LLMs utilize transformer architectures and self-attention mechanisms to analyze and generate text based on vast amounts of training data. They learn semantic representations of language patterns and context to produce coherent responses.
What is the architecture of Large Language Models?
LLMs are built upon transformer architecture, comprising multiple layers of self-attention mechanisms and feed-forward neural networks. This architecture enables them to capture contextual dependencies and generate text with high fluency and coherence.
How are Large Language Models trained?
LLMs undergo pre-training on large datasets using self-supervised learning techniques. During pre-training, they learn to predict missing words or sequences in text data, which helps them acquire a broad understanding of language patterns and semantics.
What are the applications of Large Language Models?
LLMs are used in various applications, including chatbots, virtual assistants, content generation tools, and language translation services. They facilitate human-machine interaction and drive innovation in communication and productivity.
What are some examples of Large Language Models?
Examples of LLMs include OpenAI’s GPT series (GPT-2, GPT-3), Google’s BERT, and Microsoft’s Turing-NLG. These models have demonstrated remarkable capabilities in natural language understanding and generation across diverse tasks and domains.
How do Large Language Models generate text?
LLMs generate text by predicting the next word or sequence of words based on the context provided. They use learned language patterns and semantic representations to produce coherent and contextually relevant outputs.
What are the challenges in training Large Language Models?
Challenges in training LLMs include handling large datasets, optimizing computational resources, preventing overfitting, and addressing biases in training data. Research efforts focus on developing more efficient training methodologies and mitigating these challenges.
How do Large Language Models handle bias and fairness?
LLMs can perpetuate or amplify biases present in the training data, leading to biased outputs. Addressing bias and promoting fairness in LLMs requires careful data curation, algorithmic transparency, and ongoing evaluation and mitigation efforts.
What are some ethical considerations in the use of Large Language Models?
Ethical considerations in the use of LLMs include ensuring fairness and accountability, protecting user privacy, mitigating biases, and promoting transparency in AI decision-making processes. Responsible development and deployment of LLMs are essential to address these concerns.
How do Large Language Models impact society?
LLMs have significant societal impacts, influencing communication, education, healthcare, finance, and other domains. They enhance productivity, enable personalized experiences, and raise ethical and societal considerations regarding their responsible use and deployment.
What are some potential risks associated with Large Language Models?
Risks associated with LLMs include biases in AI-generated content, privacy concerns, security vulnerabilities, and the potential for misuse or manipulation of AI technologies. Addressing these risks requires robust ethical frameworks and regulatory measures.
How can Large Language Models be used for content generation?
LLMs can generate content such as articles, blog posts, product descriptions, and social media posts based on input prompts provided by users. They leverage learned language patterns and context to produce coherent and contextually relevant text outputs.
Can Large Language Models understand multiple languages?
Yes, LLMs can understand and generate text in multiple languages, provided they have been trained on diverse multilingual datasets. They leverage their learned language representations and contextual understanding to process and generate text in different languages.
How do Large Language Models handle context in text generation?
LLMs use self-attention mechanisms to capture contextual dependencies within input sequences, allowing them to understand and generate text based on the surrounding context. This enables them to produce coherent and contextually relevant outputs.
Are there limitations to Large Language Models?
Yes, LLMs have limitations such as susceptibility to biases in training data, lack of common sense reasoning, and occasional generation of nonsensical or inappropriate text. Ongoing research aims to address these limitations and enhance the capabilities of LLMs.
What are some future trends and developments in Large Language Models?
Future trends in LLMs include advancements in architectural innovations, training methodologies, and ethical considerations. Hybrid architectures, continual learning techniques, and privacy-preserving technologies are expected to drive further progress in the field.
How can Large Language Models be used for educational purposes?
LLMs can be used for educational purposes by providing personalized tutoring, automated grading, language learning support, and educational content generation. They facilitate adaptive learning experiences tailored to individual learners’ needs and preferences.
How do Large Language Models impact content creation?
LLMs streamline content creation processes by automating the generation of text-based content such as articles, blog posts, marketing copy, and social media posts. They enable businesses and content creators to produce engaging and relevant content efficiently.
What are some considerations for deploying Large Language Models in production environments?
Considerations for deploying LLMs in production environments include model scalability, computational resources, data privacy, regulatory compliance, and user acceptance. Organizations must carefully assess these factors to ensure successful deployment and adoption of LLM-based applications.
Can Large Language Models be fine-tuned for specific tasks?
Yes, LLMs can be fine-tuned on task-specific datasets using transfer learning techniques. Fine-tuning allows LLMs to adapt to specific language tasks such as sentiment analysis, question answering, and language translation, enhancing their performance and relevance in real-world applications.
How do Large Language Models handle long documents or sequences?
LLMs use techniques such as chunking, memory optimization, and sparse attention mechanisms to handle long documents or sequences efficiently. These techniques allow them to process and generate text in a scalable and resource-efficient manner, even for lengthy input sequences.
What are some open-source resources available for Large Language Models?
Open-source resources for LLMs include pre-trained models, libraries, and frameworks such as Hugging Face’s Transformers, OpenAI’s GPT series, and Google’s TensorFlow. These resources enable researchers and developers to explore, experiment, and build upon state-of-the-art LLMs for various applications.
How do Large Language Models impact the job market?
LLMs have the potential to automate routine tasks and processes in industries such as customer service, content creation, and data analysis, potentially reshaping the job market. While they may eliminate certain roles, they also create opportunities for new jobs in AI development, data science, and machine learning engineering.
What are some best practices for evaluating Large Language Models?
Best practices for evaluating LLMs include benchmarking against standard datasets, analyzing model performance metrics, assessing computational efficiency, and conducting qualitative evaluations of generated outputs. Rigorous evaluation ensures robustness, reliability, and usability of LLMs in real-world applications.
How can Large Language Models be used for language translation?
LLMs can be used for language translation by fine-tuning them on parallel corpora of source and target language pairs. They learn to map input sequences from one language to another, enabling accurate and fluent translation of text across diverse languages and domains.
What are some challenges in deploying Large Language Models in low-resource languages?
Challenges in deploying LLMs in low-resource languages include limited training data availability, linguistic diversity, and domain-specific challenges. Research efforts focus on developing transfer learning techniques and data augmentation strategies to address these challenges and improve language understanding and generation capabilities in underrepresented languages.

")




 - Explore their architecture, training, and applications in this comprehensive guide.){kind=link}