

Key Takeaways
- The best data warehouse software in 2026 combines high performance, AI-driven automation, real-time analytics, and strong data governance to support enterprise-scale decision-making.
- No single platform fits all use cases, making it essential to align data warehouse selection with cloud strategy, data complexity, regulatory needs, and long-term business goals.
- Lakehouse architectures, multi-cloud support, and automated data management are becoming standard expectations for future-ready data warehouse platforms.
As organizations enter 2026, data has firmly established itself as the most valuable strategic asset in the digital economy. Every interaction, transaction, customer journey, and operational process now generates vast amounts of data that must be stored, processed, governed, and transformed into actionable insight. At the center of this transformation sits the modern data warehouse. What was once a static repository for historical reporting has evolved into an intelligent, cloud-first, AI-enabled platform that powers real-time analytics, machine learning, and enterprise-wide decision-making.


The growing importance of data warehousing is closely tied to several major shifts in the global technology landscape. Businesses are dealing with unprecedented data volumes, increasing data variety across structured and unstructured formats, and rising expectations for instant insights. At the same time, artificial intelligence is no longer experimental. It is embedded into everyday business workflows, from forecasting and personalization to fraud detection and operational optimization. These forces have fundamentally reshaped what organizations expect from data warehouse software in 2026.

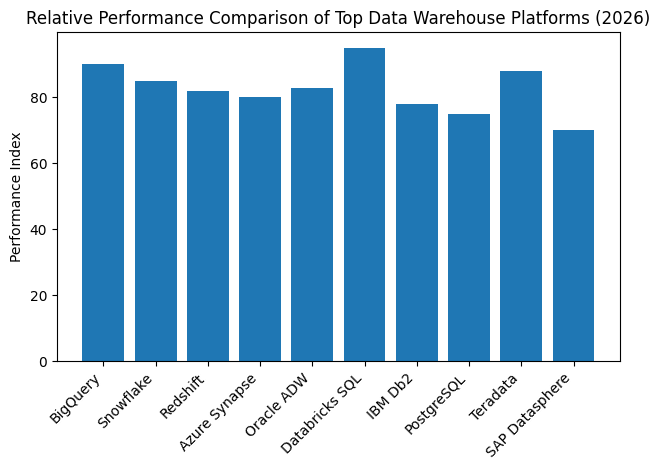
Modern data warehouses are no longer judged solely on storage capacity or query speed. Enterprises now evaluate platforms based on their ability to scale seamlessly, support real-time and streaming analytics, integrate with AI and machine learning tools, enforce strong data governance, and operate across multi-cloud and hybrid environments. As a result, choosing the right data warehouse software has become a strategic business decision rather than a purely technical one.
The Top 10 Best Data Warehouse Software To Use in 2026 reflect this new reality. Leading platforms are moving toward autonomous operations, where AI handles performance tuning, scaling, security enforcement, and even query optimization. Many are adopting lakehouse and data fabric architectures that unify data lakes and data warehouses into a single analytics layer. Others focus on deep ecosystem integration, allowing organizations to maximize the value of existing cloud investments while reducing operational complexity.

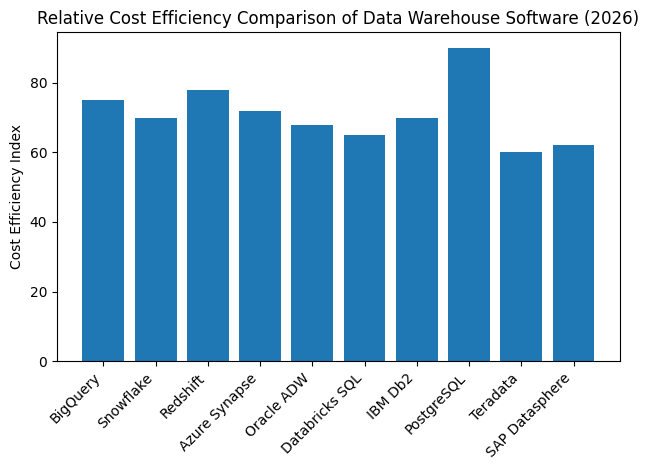
Another defining factor in 2026 is the shift from batch-based analytics to real-time intelligence. Businesses now expect data warehouses to ingest streaming data, support low-latency queries, and deliver insights as events happen. This capability is critical across industries such as finance, retail, healthcare, logistics, and technology, where speed and responsiveness directly impact competitiveness.
Security, compliance, and data trust have also become more critical than ever. With stricter global regulations and growing scrutiny around data usage, organizations must ensure that their data warehouse platforms provide not only encryption and access control, but also advanced governance features such as data lineage, metadata management, and quality monitoring. In 2026, trusted data is the foundation of reliable analytics and responsible AI.

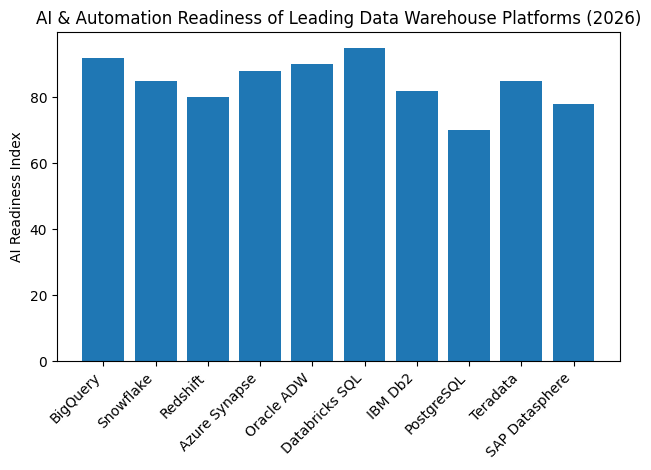
Cost efficiency adds another layer of complexity to data warehouse selection. While cloud-based, usage-driven pricing models offer flexibility, they can also introduce unpredictability if workloads are not well managed. Open-source options reduce licensing costs but increase operational responsibility. Enterprise-grade platforms promise automation and reliability, often at a higher price point. Understanding total cost of ownership is now just as important as evaluating performance and features.
This guide to the Top 10 Best Data Warehouse Software To Use in 2026 is designed to help organizations navigate this complex landscape. It provides a clear, data-driven overview of the most important platforms shaping the future of data warehousing, including solutions from Google, Amazon, Microsoft, Oracle, Databricks, and other enterprise and open-source leaders.
Throughout this article, readers will gain insight into how these platforms compare across performance, architecture, AI capabilities, security, scalability, pricing models, and deployment flexibility. Whether the goal is to support advanced machine learning workloads, enable real-time analytics, reduce operational overhead, or future-proof a data strategy, this guide offers the context needed to make an informed decision.
In 2026, data warehouses are no longer background systems quietly supporting reports. They are intelligent engines driving innovation, efficiency, and competitive advantage. Selecting the right data warehouse software today will determine how effectively organizations can adapt, grow, and succeed in an increasingly data-driven world.
Top 10 Best Data Warehouse Software To Use in 2026
- Google BigQuery
- Snowflake
- Amazon Redshift
- Microsoft Azure Synapse Analytics
- Oracle Autonomous Data Warehouse
- Databricks SQL
- IBM Db2 Warehouse
- PostgreSQL
- Teradata Vantage
- SAP Datasphere
1. Google BigQuery


Google BigQuery is widely regarded as one of the leading cloud data warehouse platforms heading into 2026. It is designed to help organizations of all sizes store, process, and analyze extremely large datasets with speed, scalability, and minimal operational effort. Its strong adoption across global enterprises, digital-native companies, and data-driven organizations reinforces its position as a top-tier data warehouse solution for modern analytics workloads.
BigQuery is especially attractive for organizations that manage large volumes of data but do not want the complexity of maintaining physical servers or tuning database infrastructure. Its cloud-native design makes it suitable for both fast-growing startups and large enterprises with complex analytics needs.
Architecture and Design Advantages
BigQuery is built on a fully serverless architecture, which means users do not need to provision, manage, or scale servers manually. This design allows teams to focus on extracting insights rather than managing infrastructure.
The platform separates storage and compute into independent layers. Data is ingested and stored in an optimized storage layer, while queries are executed in a scalable compute layer. This separation allows compute resources to scale up or down automatically based on workload demand without affecting data availability or performance.
BigQuery uses a column-based storage format that is specifically optimized for analytical queries. This enables faster scans of large datasets and reduces the amount of data processed during queries, directly contributing to lower query times and improved efficiency.
Key Architectural Benefits at a Glance
Architecture Component | Business Benefit
Serverless compute | No infrastructure management and lower operational overhead
Decoupled storage and compute | Flexible scaling and consistent performance
Columnar data storage | Faster analytics queries and reduced data scanning costs
Automatic resource allocation | Stable performance during peak workloads
Advanced Analytics and Feature Set
BigQuery offers a comprehensive set of analytics features that go beyond traditional data warehousing. It can process petabytes of data within seconds, making it suitable for real-time and near-real-time analytics use cases.
The platform includes built-in machine learning capabilities that allow users to build, train, and deploy machine learning models directly within the data warehouse using SQL. This reduces dependency on separate machine learning pipelines and accelerates time to insight.
BigQuery also supports geospatial analytics, which is valuable for location-based analysis such as logistics optimization, marketing attribution, and event tracking. Federated query capabilities allow users to analyze data stored in other Google services and external data sources without physically moving the data.
Feature Coverage Matrix
Feature Area | Capability Level
Real-time analytics | Very strong
Built-in machine learning | Native and SQL-based
Geospatial analytics | Fully supported
Cross-source querying | Supported via federated queries
Multi-cloud querying | Available through BigQuery Omni
Performance and Scalability
Performance is one of BigQuery’s strongest differentiators. The platform consistently delivers sub-second to near-real-time query responses, even when working with extremely large datasets. Organizations using BigQuery have reported dramatic reductions in query execution times compared to traditional on-premise data warehouses.
This performance advantage comes from a combination of serverless execution, columnar storage, intelligent caching, and automatic query optimization. Materialized views and cached results further reduce latency for frequently accessed queries.
Performance Impact Summary
Metric | Typical Outcome
Query execution speed | Seconds on petabyte-scale data
Performance consistency | High, even during traffic spikes
Scalability limits | Effectively unlimited for analytics workloads
Pricing Model and Cost Considerations
BigQuery uses a usage-based pricing model that charges separately for storage and query processing. Storage costs are lower for data that remains unchanged over long periods, which encourages efficient data lifecycle management. Query costs are based on the amount of data processed, offering flexibility for occasional analytics use.
While the serverless pricing model is appealing for teams that want to avoid fixed infrastructure costs, it can become expensive for organizations with heavy or unpredictable query volumes. Enterprises running frequent, complex queries may see costs rise quickly if usage is not actively monitored and optimized.
Cost Optimization Considerations
Cost Factor | Risk Level | Mitigation Strategy
High query frequency | Medium to high | Use cost controls and query optimization
Large unfiltered scans | High | Apply partitioning and clustering
Unmonitored usage | High | Set daily and monthly spend limits
Security, Compliance, and Governance
BigQuery provides enterprise-grade security by default. All data is encrypted both at rest and in transit, and access controls can be defined at very granular levels, including datasets, tables, and views. Advanced governance features support row-level and column-level security, making it suitable for sensitive and regulated data.
The platform complies with major global standards and regulations, making it a strong choice for industries such as finance, healthcare, and e-commerce. Conditional access policies further enhance security by restricting access based on time, location, or network conditions.
Ecosystem Integration and Tooling
BigQuery integrates seamlessly with the broader Google Cloud ecosystem and works well with popular data visualization, business intelligence, and analytics tools. It supports a wide range of programming languages, allowing developers and data scientists to interact with data using their preferred tools.
Built-in notebooks and SQL-based machine learning workflows enable collaborative analytics and model development directly within the platform, reducing friction between analytics and engineering teams.
User Feedback and Market Perception
User feedback consistently highlights BigQuery’s speed, scalability, and ease of use for large-scale analytics. Many users appreciate its ability to handle complex datasets without manual tuning and its strong integration with other cloud services.
Common criticisms include a learning curve for teams new to cloud data warehouses, confusion around SQL dialect variations, and cost unpredictability at scale. Some users also report limitations around data modification operations and occasional documentation gaps.
Future Roadmap and Strategic Direction
BigQuery’s future direction is strongly aligned with artificial intelligence and automation. The platform is evolving into a unified data-to-AI environment that supports structured and unstructured data, natural language interaction, and AI-assisted query generation.
Upcoming enhancements focus on deeper automation, improved governance, and tighter integration between analytics, machine learning, and operational systems. These developments position BigQuery as not just a data warehouse, but a central foundation for AI-driven decision-making in modern organizations.
Why BigQuery Ranks Among the Top Data Warehouse Software for 2026
BigQuery stands out in 2026 due to its combination of serverless simplicity, extreme scalability, high-performance analytics, and AI-native capabilities. While cost management requires discipline, its ability to deliver fast insights at global scale makes it a compelling choice for organizations prioritizing speed, flexibility, and future-ready analytics infrastructure.
2. Snowflake


Snowflake is widely recognized as one of the most advanced cloud-native data warehouse platforms available heading into 2026. It is designed for organizations that require high scalability, strong security, and the flexibility to operate across multiple cloud providers. Snowflake is particularly popular among medium to large enterprises and global teams in industries such as finance, healthcare, retail, and digital marketing, where large and complex datasets are the norm.
Snowflake’s Software-as-a-Service delivery model removes the need for infrastructure management, allowing businesses to focus entirely on analytics, reporting, and data-driven decision-making. Its ability to support multi-cloud environments makes it especially attractive for organizations pursuing long-term cloud flexibility and avoiding dependency on a single provider.
Cloud-Native Architecture and Scalability
Snowflake is built on a multi-cluster shared data architecture that cleanly separates compute from storage. This design allows organizations to scale storage and processing power independently, ensuring that performance remains consistent even as data volumes and user demand grow.
Compute resources are delivered through virtual warehouses, which are massively parallel processing clusters that can be started, paused, or resized on demand. Multiple virtual warehouses can operate on the same dataset simultaneously without performance conflicts, enabling different teams to run analytics workloads in parallel.
Architecture Benefit Matrix
Architecture Element | Practical Business Advantage
Separation of compute and storage | Independent scaling and predictable performance
Multi-cluster processing | High concurrency without query slowdowns
Cloud-agnostic deployment | Freedom to run on AWS, Azure, or Google Cloud
Automatic scaling and suspension | Efficient use of compute resources
Data Processing Capabilities and Core Features
Snowflake is designed to handle both structured and semi-structured data within a single platform. It supports standard SQL along with native handling of formats such as JSON, making it easier to analyze diverse data sources without complex preprocessing.
The platform includes advanced query optimization and acceleration features that automatically improve performance without manual tuning. Secure data sharing allows organizations to share live data with partners, customers, or internal teams without copying or exporting datasets, reducing data duplication and governance risks.
Feature Coverage Overview
Capability Area | Strength Level
Structured data analytics | Very strong
Semi-structured data handling | Strong
Secure data sharing | Native and seamless
Data lake integration | Fully supported
Concurrency management | Enterprise-grade
Performance and Query Efficiency
Snowflake delivers consistently fast query performance, even when multiple users and workloads run at the same time. It is capable of processing tens of millions of rows within seconds, making it suitable for real-time dashboards, operational analytics, and large-scale reporting.
The platform continuously improves performance through internal optimizations, many of which are applied automatically without customer intervention. This ongoing optimization ensures that organizations benefit from faster queries over time without needing to reconfigure their environments.
Performance Snapshot
Metric | Typical Outcome
Large query execution | Seconds on millions of rows
Concurrent workloads | Stable and predictable
Performance improvements | Continuous and automatic
Pricing Model and Cost Management Considerations
Snowflake uses a consumption-based pricing model that charges separately for compute and storage. Compute usage is billed per second with a short minimum duration, allowing precise cost control when workloads are well managed. Storage pricing includes built-in backup and failover, reducing additional operational expenses.
While this pricing model can be cost-effective for variable or moderate workloads, costs can rise quickly in high-usage environments if virtual warehouses are not carefully monitored. Organizations with unpredictable or heavy query volumes must actively manage usage to avoid unexpected spending.
Cost Risk and Control Matrix
Cost Factor | Potential Risk | Recommended Practice
Always-on compute clusters | High cost buildup | Use auto-suspend aggressively
Large concurrent workloads | Cost spikes | Isolate workloads by virtual warehouse
Unmonitored usage | Budget overruns | Implement usage alerts and limits
Security, Compliance, and Data Governance
Security is a core strength of Snowflake. All data is encrypted end-to-end, and access is controlled through role-based permissions and multi-factor authentication. The platform supports strict governance requirements and complies with major global regulations, making it suitable for highly regulated industries.
Snowflake also includes intelligent monitoring features that help detect unusual behavior, configuration drift, and potential security risks. These capabilities reduce the operational burden on security teams while improving overall data protection.
Ecosystem Integration and Connectivity
Snowflake integrates smoothly with a wide range of data ingestion, transformation, analytics, and visualization tools. It supports common programming languages and frameworks, allowing developers and data engineers to work within familiar environments.
Native connectors and a large ecosystem of third-party integrations make it easy to connect streaming platforms, data lakes, business intelligence tools, and machine learning frameworks. The Snowflake Marketplace further extends functionality by providing access to shared and third-party datasets.
User Feedback and Market Standing
User feedback consistently highlights Snowflake’s strong performance on large datasets, intuitive interface, and ability to scale without manual intervention. Many users value its multi-cloud flexibility, secure data sharing, and the absence of server maintenance responsibilities.
Common concerns include rising costs at scale, occasional latency during rapid scaling events, and limitations when working with highly unstructured data. Some organizations also note that achieving optimal performance and cost efficiency requires experienced configuration and governance.
Strategic Roadmap and AI-Focused Direction
Snowflake’s long-term strategy is centered on becoming a full AI Data Cloud rather than a traditional data warehouse. The platform is expanding its native machine learning and AI capabilities, enabling organizations to build, deploy, and manage models directly where the data lives.
Future developments emphasize automation, generative AI, conversational analytics, and simplified end-to-end machine learning workflows. These initiatives aim to position Snowflake as a central platform for data-driven applications, analytics, and AI-powered business processes.
Why Snowflake Is a Top Data Warehouse Choice for 2026
Snowflake earns its place among the top data warehouse software options for 2026 due to its scalable architecture, strong performance, enterprise-grade security, and forward-looking AI strategy. While cost control requires careful governance, its flexibility, reliability, and continuous innovation make it a compelling choice for organizations seeking a future-ready data platform.
3. Amazon Redshift

Amazon Redshift is widely recognized as one of the most established and scalable cloud data warehouse platforms going into 2026. It is designed to support high-speed analytics across very large datasets, ranging from terabytes to petabytes and beyond. Redshift is commonly used by medium to large enterprises that require reliable performance, deep cloud integration, and the ability to analyze data from multiple sources such as data warehouses, operational databases, and data lakes.
Its strong adoption among global brands across industries such as retail, healthcare, media, and technology highlights its maturity and suitability for mission-critical analytics workloads. For organizations already invested in the AWS ecosystem, Redshift often becomes a natural choice due to its seamless interoperability with other AWS services.
Core Architecture and Scalability Strengths
Amazon Redshift is built on a Massively Parallel Processing architecture, which distributes workloads across multiple compute nodes to deliver fast query execution. This approach allows Redshift to process very large datasets efficiently by dividing queries into smaller tasks that run in parallel.
The platform supports both row-based and column-based storage, with columnar storage playing a key role in accelerating analytical queries. Automatic concurrency scaling allows Redshift to handle hundreds of simultaneous users and queries without performance degradation, making it suitable for analytics teams with diverse and overlapping workloads.
Architecture Capability Matrix
Architecture Component | Business Impact
MPP-based compute engine | Fast processing of large datasets
Columnar storage | High-performance analytical queries
Concurrency scaling | Stable performance with many users
AWS-native integration | Unified data ecosystem and workflows
Advanced Analytics and Feature Capabilities
Redshift supports standard SQL, making it accessible to analysts and engineers without the need to learn proprietary query languages. It can analyze structured, semi-structured, and selected unstructured data directly, reducing the need for complex preprocessing pipelines.
Key performance-enhancing features include result caching, materialized views, and an advanced query accelerator that reduces execution time for repetitive or complex queries. Machine learning–based workload management automatically prioritizes and balances workloads to maintain consistent performance.
Feature Coverage Overview
Analytics Capability | Strength Level
Large-scale SQL analytics | Very strong
Semi-structured data analysis | Strong
Query acceleration | Built-in and automated
Workload management | AI-assisted
Data lake integration | Deep and native
Performance and Throughput at Scale
Amazon Redshift is known for delivering high-speed analytics, even as data volumes and query complexity increase. It is capable of scanning and processing petabytes of data within seconds, making it suitable for dashboards, reporting, and advanced analytical use cases.
As workloads scale, Redshift emphasizes price-to-performance efficiency, particularly for organizations that optimize cluster configurations and leverage reserved capacity. Benchmarking frameworks such as TPC-DS are commonly used to evaluate Redshift’s performance in real-world analytical scenarios.
Performance Snapshot
Metric | Typical Outcome
Query execution speed | Seconds on petabyte-scale data
Concurrent query handling | Hundreds of simultaneous queries
Throughput at scale | Consistent under heavy workloads
Pricing Model and Cost Management Considerations
Amazon Redshift offers multiple pricing models to support different usage patterns. Organizations can choose provisioned clusters with hourly pricing or managed storage pricing based on the amount of data stored. Reserved capacity options provide significant long-term savings for predictable workloads.
However, Redshift is not fully serverless by default, which means organizations must actively manage cluster sizes, instance types, and scaling policies. Without careful planning, costs can rise with large datasets, frequent queries, or heavy use of complementary AWS services.
Cost Risk and Optimization Matrix
Cost Driver | Risk Level | Recommended Approach
Over-provisioned clusters | Medium to high | Right-size clusters regularly
High query volume | Medium | Use caching and materialized views
Unreserved capacity | High | Commit to reserved instances where possible
Security, Compliance, and Governance
Security is a major focus area for Amazon Redshift, especially with recent enhancements that enable secure configurations by default. New clusters and serverless workgroups now start with encryption enabled, public access disabled, and secure connections enforced.
Redshift supports encryption both in transit and at rest, along with network isolation and fine-grained access controls. Row-level and column-level permissions help organizations enforce strict data governance policies. Compliance with major global standards makes Redshift suitable for regulated industries.
Ecosystem Integration and AWS Synergy
One of Redshift’s strongest advantages is its deep integration with the broader AWS ecosystem. It connects seamlessly with data ingestion, streaming, storage, analytics, and machine learning services, enabling end-to-end data pipelines within a single cloud environment.
Redshift also integrates well with popular business intelligence platforms and third-party data integration tools, making it easier for organizations to connect analytics outputs to reporting and visualization layers.
User Feedback and Market Perception
User feedback frequently highlights Redshift’s scalability, performance on complex queries, and strong security controls. Many users value its tight integration with AWS services, reliable support, and ability to handle both structured and semi-structured data efficiently.
Common challenges include the effort required for migration, the need for well-optimized SQL to avoid performance issues, and rising costs when multiple AWS services are used together. Some users also note limits around cluster size, data types, and real-time streaming capabilities.
Strategic Roadmap and AI-Driven Direction
Amazon Redshift’s roadmap reflects a broader shift beyond traditional data warehousing. The platform is increasingly incorporating AI-driven optimizations, automated scaling, and advanced analytics capabilities. Zero-ETL integrations are reducing latency between transactional systems and analytical workloads.
Generative AI integrations are enabling natural language query experiences and lowering the barrier to advanced analytics. These developments position Redshift as a more intelligent, secure, and accessible analytics platform for enterprise users.
Why Amazon Redshift Is a Top Data Warehouse Choice for 2026
Amazon Redshift earns its place among the top data warehouse software options for 2026 due to its proven scalability, strong performance, enterprise-grade security, and deep AWS integration. While cost and operational management require attention, especially in non-serverless deployments, its maturity and continuous innovation make it a compelling choice for organizations seeking powerful cloud-based analytics at scale.
4. Microsoft Azure Synapse Analytics


Microsoft Azure Synapse Analytics is widely regarded as one of the most comprehensive enterprise analytics and data warehouse platforms available going into 2026. It is designed for large organizations that need to analyze massive volumes of data from many different sources while maintaining strong governance, security, and performance. The platform is commonly used by global enterprises with complex reporting, regulatory, and advanced analytics requirements, making it a strong contender among the top data warehouse solutions for large-scale environments.
Azure Synapse is especially attractive to organizations already invested in the Microsoft ecosystem, as it brings data warehousing, big data analytics, and advanced reporting into a single, unified environment.
Unified Architecture and Platform Design
Azure Synapse Analytics combines traditional data warehousing and big data analytics into one integrated platform. It allows teams to work with SQL-based analytics, Apache Spark, and other big data tools from a single workspace. This unified approach reduces system complexity and improves collaboration between data engineers, analysts, and data scientists.
The platform is built on a Massively Parallel Processing architecture, enabling it to distribute workloads across many compute nodes for fast query execution. Storage and compute resources can scale independently, allowing organizations to handle growing data volumes without redesigning their architecture.
Architecture Capability Matrix
Architecture Component | Business Advantage
Unified SQL and Spark environment | One platform for analytics and big data
MPP-based processing | Faster execution on large datasets
Independent compute and storage scaling | Flexibility for changing workloads
Multi-language support | Broader access for analytics teams
Data Handling and Analytics Capabilities
Azure Synapse supports structured, semi-structured, and unstructured data, making it suitable for modern data ecosystems that combine transactional data, logs, events, and external data feeds. The platform includes native integrations with dozens of data sources, allowing organizations to ingest and analyze data from across their digital operations.
Advanced performance features such as workload classification, workload isolation, materialized views, and result caching help maintain consistent performance even when many users run complex queries at the same time. Flexible indexing options further improve query speed for large analytical tables.
Feature Coverage Overview
Analytics Capability | Strength Level
Enterprise data warehousing | Very strong
Big data analytics | Strong
Parallel query execution | Enterprise-grade
Indexing and caching | Highly configurable
Machine learning integration | Native via Azure services
Performance at Enterprise Scale
Azure Synapse delivers fast query performance when operating at enterprise scale. Analytical queries on very large datasets can be executed in seconds, especially when tables exceed terabytes in size and contain billions of rows. This makes it well suited for financial reporting, operational analytics, and advanced business intelligence use cases.
The platform is optimized for parallel workloads, allowing multiple teams to run queries simultaneously without severe performance degradation. Spark workloads also benefit from optimized execution engines that significantly improve processing speed compared to standard open-source configurations.
Performance Snapshot
Metric | Typical Outcome
Large analytical queries | Seconds on multi-terabyte data
Concurrent workloads | Stable with proper configuration
Spark execution speed | Significantly faster than standard Spark
Pricing Structure and Cost Considerations
Azure Synapse Analytics uses a flexible pricing model that separates compute, storage, and data processing costs. Organizations can scale compute resources up or down based on workload requirements and reduce costs through reserved capacity commitments.
While this flexibility is valuable for large enterprises, costs can vary significantly depending on usage patterns. For smaller teams or simpler analytics needs, the platform may be more complex and expensive than necessary, making it most suitable for organizations operating at scale.
Cost Management Matrix
Cost Driver | Risk Level | Optimization Strategy
High compute usage | Medium to high | Schedule and pause unused resources
Large data volumes | Medium | Optimize storage tiers and indexing
Unreserved capacity | High | Use long-term reservations
Security, Compliance, and Governance
Security and compliance are major strengths of Azure Synapse Analytics. The platform provides granular access controls at the schema, table, column, and row levels. Data is always encrypted both in transit and at rest, ensuring strong baseline protection for sensitive information.
Additional features such as dynamic data masking and integration with Microsoft’s data governance tools help organizations meet regulatory and internal compliance requirements. Azure Synapse supports major global standards, making it suitable for regulated industries such as finance, healthcare, and government.
Integration with the Microsoft Ecosystem
One of the key advantages of Azure Synapse is its deep integration with Microsoft’s analytics and cloud services. It works seamlessly with reporting, identity, machine learning, data integration, and real-time analytics tools, enabling end-to-end data pipelines within a single ecosystem.
The platform also integrates with widely used third-party analytics and visualization tools, allowing organizations to maintain flexibility in how insights are consumed and shared across the business.
User Feedback and Market Perception
User feedback consistently highlights Azure Synapse’s ability to unify big data and data warehousing in one platform. Many users value its scalability, tight integration with Microsoft tools, and its suitability for complex enterprise analytics environments.
Common challenges include the need for Azure-specific expertise to configure and manage the platform effectively, limitations in certain SQL features, and the absence of built-in data quality or profiling tools. Some users also report that performance tuning requires careful planning to achieve optimal results.
Strategic Direction and Future Outlook
Microsoft’s long-term strategy is evolving Azure Synapse into a broader, more integrated analytics experience under the Microsoft Fabric vision. This direction emphasizes a lake-centric architecture, tighter integration with reporting tools, and simplified analytics workflows across data engineering, warehousing, and business intelligence.
The platform continues to invest in AI-driven analytics, regulatory support, real-time and batch processing, and continuous platform enhancements. This strategic evolution ensures that Azure Synapse remains relevant as enterprise analytics needs grow more complex.
Why Azure Synapse Analytics Is a Top Data Warehouse Choice for 2026
Microsoft Azure Synapse Analytics earns its place among the top data warehouse software options for 2026 due to its unified analytics approach, enterprise-grade scalability, strong security, and deep ecosystem integration. While it is best suited for large and complex environments, organizations operating at scale benefit from its flexibility, performance, and future-ready analytics capabilities.
5. Oracle Autonomous Data Warehouse

Oracle Autonomous Data Warehouse is widely recognized as one of the most advanced automated data warehouse platforms available for enterprise use in 2026. It is designed for organizations that want high-performance analytics without the operational burden of managing databases manually. By using built-in artificial intelligence to automate core database tasks, the platform significantly reduces human effort, lowers operational risk, and improves consistency across complex data environments.
Oracle Autonomous Data Warehouse is especially valuable for large enterprises, regulated industries, and marketing or analytics teams handling massive datasets without dedicated database administrators. Its ability to support data warehouses, data marts, data lakes, and lakehouse architectures makes it a versatile solution for modern data strategies.
Cloud-Native Architecture and Intelligent Automation
Oracle Autonomous Data Warehouse is built specifically for the cloud and runs on Oracle Exadata infrastructure. This foundation enables high throughput, low latency, and consistent performance for analytical workloads. What sets the platform apart is its deep automation layer, which continuously monitors and optimizes the system without manual intervention.
Key operational tasks such as indexing, tuning, scaling, patching, and backups are handled automatically using AI-driven controls. This self-managing approach reduces downtime, minimizes configuration errors, and ensures optimal performance even as workloads change.
Architecture and Automation Benefits
Capability Area | Practical Advantage for Enterprises
Self-tuning and auto-indexing | Faster queries without manual optimization
Automatic scaling | Resources adjust instantly to workload demand
Self-patching | Always up to date with minimal disruption
Exadata-optimized engine | High-performance analytics at scale
Analytics Capabilities and Data Flexibility
Oracle Autonomous Data Warehouse is optimized for analytical workloads and supports a wide range of data models. It can operate as a traditional enterprise data warehouse, a modern data lakehouse, or a centralized analytics hub. The platform supports structured and semi-structured data and is designed to handle complex analytical queries efficiently.
Built-in AI analytics allow organizations to generate insights directly within the data platform. Advanced features such as Hybrid Columnar Compression and Smart Scan reduce storage usage while accelerating query execution, making it suitable for data-intensive environments.
Feature Capability Overview
Analytics Feature | Strength Level
Enterprise data warehousing | Very strong
Data lake and lakehouse support | Strong
AI-driven analytics | Native and integrated
Hybrid cloud compatibility | Fully supported
Real-time insight generation | Enterprise-ready
Performance, Scalability, and Operational Efficiency
Performance is a major strength of Oracle Autonomous Data Warehouse. New instances can be provisioned and made operational within minutes, allowing teams to respond quickly to changing business needs. The platform supports scaling compute resources up or down without downtime, ensuring uninterrupted analytics during peak demand.
AI-driven automation directly contributes to faster query performance and lower operational costs. Independent industry analysis has shown significant reductions in database management overhead, making the platform attractive for organizations with large, dynamic workloads that require reliability and speed.
Performance and Efficiency Snapshot
Metric | Typical Outcome
Provisioning time | Minutes
Query performance | Optimized automatically
Scaling impact | No downtime during scaling
Operational overhead | Significantly reduced
Pricing Structure and Cost Considerations
Oracle Autonomous Data Warehouse uses a consumption-based pricing model, allowing organizations to pay based on actual usage. This approach provides flexibility for large enterprises that need to scale resources dynamically. However, the platform can be costly for smaller businesses due to higher licensing and infrastructure costs.
Organizations that are already heavily invested in the Oracle ecosystem often find the pricing more justifiable, while those outside the Oracle stack may perceive a higher level of vendor dependency. As a result, Oracle Autonomous Data Warehouse is generally best suited for enterprise-scale deployments rather than small teams or lightweight analytics needs.
Cost and Suitability Matrix
Organization Type | Cost Fit Assessment
Large enterprises | Strong fit
Regulated industries | Strong fit
Mid-sized organizations | Moderate fit
Small teams | Limited fit
Security, Compliance, and Data Protection
Security and compliance are core strengths of Oracle Autonomous Data Warehouse. The platform includes transparent encryption by default, advanced key management, and strict access controls with multi-factor authentication. Sensitive data can be automatically classified, masked, or redacted to meet regulatory requirements.
Additional protections include database activity monitoring, immutable automated backups, consolidated auditing, and real-time threat detection. These capabilities make the platform suitable for industries with strict compliance and governance requirements.
Integration and Ecosystem Connectivity
Oracle Autonomous Data Warehouse integrates tightly with Oracle’s analytics, AI, and data integration services, enabling a unified data and analytics experience. It also supports open data formats such as Delta Lake, Parquet, Iceberg, and Hudi, allowing organizations to work with modern data architectures.
The platform connects seamlessly with business intelligence tools, data engineering frameworks, and enterprise applications, making it easier to embed analytics into operational workflows. Native support for AI and machine learning services further enhances its role as a central data intelligence platform.
User Feedback and Market Perception
User feedback consistently highlights the platform’s speed, stability, and ease of use once deployed. Many users appreciate that it delivers the full power of Oracle Database on Exadata infrastructure without requiring teams to manage operating systems, clusters, or manual upgrades.
Common concerns focus on cost, especially for smaller organizations, and the learning curve for teams without prior Oracle experience. Some users also point out limitations in certain programming language integrations and network configuration flexibility. Despite these concerns, overall satisfaction remains very high among enterprise users.
Strategic Roadmap and Future Direction
Oracle’s long-term vision for Autonomous Data Warehouse centers on a unified data lakehouse approach that blends data warehousing, data lakes, and AI-driven analytics. The roadmap emphasizes hybrid and multicloud deployments, enabling organizations to analyze data across environments without fragmentation.
Future enhancements focus on deeper AI and machine learning integration, natural language interaction with data, and end-to-end support for data engineering, analytics, and AI workloads. This strategy positions Oracle Autonomous Data Warehouse as a comprehensive, self-managing data platform for complex enterprise ecosystems.
Why Oracle Autonomous Data Warehouse Is a Top Data Warehouse Choice for 2026
Oracle Autonomous Data Warehouse stands out in 2026 due to its unmatched automation, enterprise-grade security, high performance, and strong support for modern data architectures. While it is best suited for large organizations with complex requirements, its hands-off management model, scalability, and AI-driven optimization make it one of the most powerful and future-ready data warehouse platforms available.
6. Databricks SQL

Databricks SQL is widely regarded as one of the most powerful and future-ready data warehouse solutions for 2026. It is built for organizations that need to work with very large datasets while combining analytics, data engineering, and machine learning in a single environment. Databricks SQL is especially attractive to large enterprises and data-driven organizations that require high performance, advanced analytics, and strong governance across both structured and unstructured data.
What makes Databricks SQL stand out is its lakehouse approach, which merges the flexibility of data lakes with the reliability and performance of traditional data warehouses. This unified model removes the need to maintain separate systems for analytics and machine learning, simplifying modern data architectures.
Lakehouse Architecture and Platform Design
Databricks SQL is built on a lakehouse architecture that allows data teams to run analytics, business intelligence, and machine learning workloads directly on the same data. This approach eliminates data duplication and reduces complexity across data pipelines.
The platform offers serverless SQL warehouses that automatically scale resources up or down based on workload demand. This removes the need for manual infrastructure management and ensures consistent performance during peak usage. Multiple warehouse types are available, allowing organizations to choose between cost efficiency, enhanced performance, or fully automated execution.
Architecture Capability Matrix
Architecture Element | Business Benefit
Lakehouse data model | Unified analytics and AI on one data layer
Serverless SQL warehouses | No infrastructure management
Distributed Spark engine | High performance at massive scale
Delta Lake foundation | Reliable transactions and schema evolution
Data Processing and Analytics Capabilities
Databricks SQL supports both batch and real-time data processing, making it suitable for operational analytics, dashboards, and advanced data science use cases. It works with multiple programming languages, enabling analysts, engineers, and data scientists to collaborate within the same platform.
Delta Lake adds enterprise-grade reliability through ACID transactions, versioning, and time travel, which allows teams to track data changes and recover previous states easily. Unified governance ensures that data access, quality, and compliance are consistently enforced across all workloads.
Feature Coverage Overview
Capability Area | Strength Level
SQL analytics | Very strong
Machine learning workflows | Industry-leading
Real-time and batch processing | Fully supported
Data governance | Centralized and unified
Multi-language support | Extensive
Performance Leadership and Scalability
Performance is one of Databricks SQL’s strongest differentiators. The platform consistently demonstrates leadership in industry benchmarks, particularly for large-scale analytics and data loading workloads. Continuous engine optimizations have resulted in significant performance improvements across BI queries, ETL pipelines, and exploratory analytics.
This focus on performance ensures that Databricks SQL can handle complex analytical queries and machine learning workloads with high throughput, making it suitable for organizations that operate at petabyte scale.
Performance Snapshot
Metric | Typical Outcome
Large query execution | Extremely fast at scale
Data loading throughput | Industry-leading
Performance improvements | Continuous and automatic
Concurrency handling | Strong for mixed workloads
Pricing Structure and Cost Considerations
Databricks SQL uses a usage-based pricing model that combines Databricks Units with underlying cloud compute costs. This model provides flexibility for organizations with variable workloads, but it can be difficult to estimate costs without careful monitoring.
For large enterprises running continuous production workloads, costs can increase quickly. As a result, Databricks SQL is often viewed as best suited for organizations that can fully leverage its advanced capabilities. Smaller or mid-sized businesses may find the platform more complex and costly than necessary for simpler analytics needs.
Cost and Suitability Matrix
Organization Size | Cost Efficiency Assessment
Large enterprises | Strong fit
Data science–heavy teams | Strong fit
Mid-sized organizations | Moderate fit
Basic analytics teams | Limited fit
Security, Compliance, and Governance
Databricks places strong emphasis on security and governance through a unified control layer that manages access to data, analytics, and AI assets. This centralized approach simplifies compliance and reduces the risk of inconsistent permissions across systems.
The platform meets major global compliance standards, making it suitable for regulated industries such as healthcare, finance, and enterprise technology. Governance features extend across all data assets, supporting fine-grained access controls and auditability.
Integration and Ecosystem Connectivity
Databricks SQL integrates with a wide range of data formats, cloud storage services, analytics tools, and orchestration platforms. This flexibility allows organizations to build end-to-end data pipelines without being locked into a single toolset.
Native integration with machine learning lifecycle management tools enables teams to move seamlessly from data preparation to model deployment. Business intelligence tools can connect directly to Databricks SQL, making insights accessible to non-technical users.
User Feedback and Market Perception
User feedback consistently highlights Databricks SQL as a powerful all-in-one platform that brings together data engineering, analytics, and machine learning. Many users value its performance, scalability, and ability to handle complex workloads in a unified environment.
Common concerns include higher costs for always-on production pipelines, browser resource usage, and limited customization options for dashboards. Some organizations also view the platform as overly complex for simpler analytics use cases. Despite these drawbacks, satisfaction remains high among enterprises with advanced data needs.
Strategic Roadmap and Future Direction
Databricks continues to invest heavily in performance, usability, and AI-driven analytics. The roadmap emphasizes simplifying advanced analytics through AI-assisted query building, improved visualization features, and faster user interface interactions.
Governance enhancements and expanded SQL capabilities are designed to make the platform more accessible to traditional analytics users while maintaining its strength in data science. This convergence of BI and AI signals a long-term strategy to democratize advanced analytics on a single, open platform.
Why Databricks SQL Is a Top Data Warehouse Choice for 2026
Databricks SQL earns its place among the top data warehouse software options for 2026 due to its lakehouse architecture, exceptional performance, and deep integration of analytics and machine learning. While it may be complex and costly for smaller teams, organizations operating at scale benefit from its unified design, performance leadership, and strong governance, making it one of the most capable data platforms for modern enterprise analytics.
7. IBM Db2 Warehouse

IBM Db2 Warehouse is a fully managed, cloud-based data warehouse platform designed to support modern analytics, business intelligence, and AI-driven insights. It is built for organizations that need reliable performance, strong security, and the flexibility to operate across cloud and on-premises environments. Going into 2026, IBM Db2 Warehouse stands out as a strong choice for enterprises that require hybrid cloud readiness, operational analytics, and built-in intelligence within their data infrastructure.
The platform has gained notable traction among midsize enterprises and educational institutions, largely due to its balance of enterprise-grade capabilities and flexible deployment options. Its ability to serve data engineers, developers, analysts, and data scientists within a single environment makes it suitable for diverse analytics teams.
Core Architecture and Hybrid Cloud Design
IBM Db2 Warehouse is powered by the IBM BLU Acceleration engine, an in-memory, columnar analytics technology designed for high-speed query execution on large datasets. This engine allows the platform to process complex analytical workloads efficiently while minimizing latency.
The platform is built with Massively Parallel Processing, enabling it to distribute queries across multiple nodes and handle hundreds of concurrent users. Its containerized deployment on Kubernetes allows Db2 Warehouse to run consistently across public cloud, private cloud, and on-premises environments, making it particularly attractive for organizations with hybrid or multi-environment IT strategies.
Architecture Capability Matrix
Architecture Element | Business Value
In-memory columnar engine | Faster analytics on large datasets
MPP architecture | High concurrency and parallel execution
Kubernetes-based deployment | True hybrid and portable architecture
Elastic scaling | Adjust resources based on workload demand
Analytics, AI, and Multi-Workload Support
IBM Db2 Warehouse is designed to support a wide range of analytics use cases beyond traditional reporting. It includes built-in machine learning capabilities, allowing teams to run predictive and AI-driven analytics directly within the data warehouse. This reduces the need for exporting data to separate systems for advanced analysis.
The platform supports multiple data models and workloads, including relational, JSON, geospatial, graph, and predictive analytics. Federated query capabilities allow organizations to query data across cloud and on-premises Db2 environments without extensive data movement, providing a unified view of enterprise data.
Feature Coverage Overview
Capability Area | Strength Level
Operational analytics | Strong
Business intelligence | Enterprise-grade
Built-in machine learning | Integrated
Geospatial and predictive analytics | Supported
Federated data access | Native
Performance, Scalability, and Real-Time Insights
Performance is one of the key reasons IBM Db2 Warehouse is considered a top data warehouse option for 2026. Users consistently report fast data ingestion, low query latency, and stable performance even with very large datasets. The platform is capable of supporting real-time analytics scenarios where timely insights are critical.
Its elastic scaling model allows organizations to increase or reduce compute capacity as workloads change, helping maintain performance during peak usage while controlling costs during quieter periods. This scalability across hybrid environments is particularly valuable for enterprises with fluctuating analytics demands.
Performance Snapshot
Metric | Typical Outcome
Query response time | Fast and consistent
Concurrent queries | Hundreds supported
Real-time data access | Fully supported
Scalability impact | Minimal performance degradation
Pricing Structure and Cost Considerations
IBM Db2 Warehouse offers multiple pricing tiers, ranging from entry-level options to elastic compute configurations designed for demanding enterprise workloads. Pricing is typically based on instance size and cluster configuration, with higher tiers offering greater performance and scalability.
While the platform delivers strong value for enterprise use cases, it may require higher upfront investment, particularly for reserved capacity or premium editions. As a result, it is often better suited for organizations that can fully utilize its advanced capabilities rather than very small teams with lightweight analytics needs.
Cost and Suitability Matrix
Organization Type | Cost Fit Assessment
Large enterprises | Strong fit
Midsize enterprises | Good fit
Educational institutions | Good fit
Small teams | Moderate to limited fit
Security, Compliance, and Data Protection
Security is a major strength of IBM Db2 Warehouse. The platform provides end-to-end encryption, secure connections, and strong authentication mechanisms to protect sensitive data. It supports industry-standard security protocols and cryptographic providers, ensuring data is protected both in transit and at rest.
Db2 Warehouse complies with a wide range of global and industry-specific standards, making it suitable for regulated sectors such as healthcare, finance, and government. These compliance capabilities reduce the burden on organizations operating in complex regulatory environments.
Integration and Ecosystem Connectivity
IBM Db2 Warehouse integrates easily with a broad ecosystem of analytics, BI, and data integration tools. It works seamlessly with IBM’s analytics and AI offerings while also supporting leading third-party visualization and ETL platforms.
Support for open data formats such as Parquet, Iceberg, ORC, and CSV enables secure data sharing and interoperability across the enterprise. This openness allows organizations to avoid data silos and maintain flexibility in their data architecture.
User Feedback and Market Perception
User reviews frequently highlight IBM Db2 Warehouse’s stability, performance, scalability, and strong security posture. Many users appreciate its resilience, high availability, and ability to handle large data volumes reliably. Enterprise support quality is also often cited as a positive factor.
At the same time, some users report a steep learning curve and complexity during initial setup. Others note that new features may roll out more slowly compared to newer cloud-native competitors, and that the user interface and tooling can feel less modern. Documentation depth and consistency are also mentioned as areas for improvement.
Strategic Roadmap and Future Direction
IBM’s roadmap for Db2 Warehouse places strong emphasis on hybrid cloud expansion and AI-powered database management. Recent developments focus on intelligent automation, enhanced data virtualization, and improved connectivity between cloud and on-premises data sources.
Future enhancements aim to strengthen security, scalability, and support for emerging workloads while simplifying management through AI-driven tools. This direction reflects IBM’s broader strategy of supporting complex enterprise data landscapes that span multiple environments.
Why IBM Db2 Warehouse Is a Top Data Warehouse Choice for 2026
IBM Db2 Warehouse earns its position among the top data warehouse software options for 2026 due to its strong performance, hybrid cloud flexibility, enterprise-grade security, and built-in AI capabilities. While it requires investment and expertise to deploy effectively, organizations with complex, regulated, or hybrid data environments benefit from its stability, scalability, and comprehensive analytics support.
8. PostgreSQL

PostgreSQL is one of the most widely adopted open-source relational database systems in the world and continues to gain relevance as a data warehouse foundation in 2026. Known for its reliability, flexibility, and strong performance with complex queries, PostgreSQL is increasingly used not only for transactional systems but also for analytical workloads and entry-to-mid level data warehousing use cases.
Its open-source nature makes it especially attractive to startups, growing companies, and cost-conscious enterprises that want full control over their data infrastructure. Many organizations use PostgreSQL as a stepping stone toward larger cloud data warehouses, while others successfully scale it into a core analytics platform with the right architecture and expertise.
Core Architecture and Technical Foundations
PostgreSQL is built on a mature relational database architecture with strong support for complex data models and advanced SQL capabilities. A key architectural strength is its Multi-Version Concurrency Control mechanism, which allows multiple users to read and write data simultaneously without blocking each other. This design ensures high consistency and stable performance even under concurrent workloads.
The platform supports both traditional relational data and modern data formats such as JSON, making it suitable for mixed workloads. Its object-relational design allows developers to define custom data types, functions, and extensions, giving PostgreSQL a level of flexibility that many proprietary systems lack.
Architecture Capability Matrix
Architecture Component | Practical Value for Analytics
MVCC concurrency model | High consistency and parallel query execution
Advanced SQL engine | Strong support for complex analytical queries
Object-relational design | Flexible data modeling and extensibility
Infrastructure-agnostic deployment | Runs on cloud or on-premises
Analytics Capabilities and Extensibility
PostgreSQL excels at handling complex analytical queries involving joins, aggregations, window functions, and common table expressions. These features are critical for reporting, analytics, and data transformation workloads. The platform also supports JSON querying, enabling hybrid relational and semi-structured analytics within the same database.
Through extensions, PostgreSQL can be enhanced for specialized analytics use cases. For example, geospatial analytics can be enabled with spatial extensions, while other extensions support full-text search, time-series data, and advanced indexing strategies. This extensibility allows PostgreSQL to evolve alongside business needs.
Feature Coverage Overview
Analytics Feature | Strength Level
Complex SQL analytics | Very strong
JSON and semi-structured data | Strong
Geospatial analytics | Supported via extensions
Custom functions and types | Native
Extension ecosystem | Extensive
Performance and Scalability Characteristics
PostgreSQL is widely recognized for its strong performance with complex queries and large datasets when properly tuned. Each major release typically introduces meaningful performance improvements, particularly in query planning, indexing, and parallel execution. In many real-world scenarios, PostgreSQL delivers faster performance than other open-source databases for analytical workloads.
That said, PostgreSQL does not provide automatic scaling out of the box. Scaling typically requires architectural decisions such as read replicas, partitioning, sharding, or the use of external orchestration tools. As a result, PostgreSQL performs best in environments where teams are comfortable managing performance and scaling manually.
Performance Snapshot
Metric | Typical Outcome
Complex query execution | Fast and reliable
Parallel query support | Strong
Release-to-release gains | Consistent performance improvements
Scaling effort | Manual and architecture-dependent
Cost Structure and Operational Considerations
One of PostgreSQL’s strongest advantages is cost. The software itself is completely free to use, with no licensing fees. Organizations only pay for the infrastructure on which it runs, whether in the cloud or on-premises. This makes PostgreSQL highly attractive for organizations seeking to minimize software costs.
However, operational costs must be considered. PostgreSQL requires manual management for tasks such as scaling, backups, upgrades, performance tuning, and security hardening. For teams without dedicated database expertise, these operational demands can represent a hidden cost that offsets the savings from free licensing.
Cost and Suitability Matrix
Organization Type | Cost Efficiency Assessment
Startups and small teams | Strong fit
Midsize organizations | Strong fit with DBA support
Large enterprises | Selective fit for analytics use cases
Hands-off teams | Limited fit
Security, Reliability, and Data Integrity
PostgreSQL is fully ACID-compliant, ensuring strong data integrity and reliable transaction handling. It includes robust role-based access controls, authentication mechanisms, and permission management to protect sensitive data.
Security posture largely depends on how PostgreSQL is deployed and managed. While the database provides the necessary building blocks for secure systems, compliance with industry regulations often requires additional configuration, infrastructure controls, and governance processes implemented by the organization.
Ecosystem Integration and Tool Compatibility
PostgreSQL benefits from a vast global open-source community and a rich ecosystem of tools. It integrates seamlessly with major cloud providers and works with a wide range of ETL, data integration, and analytics platforms.
This broad compatibility makes PostgreSQL easy to embed into modern data stacks, whether as a standalone analytics store or as part of a larger data pipeline feeding downstream warehouses or BI tools.
User Adoption and Market Perception
PostgreSQL continues to grow rapidly in popularity among developers and enterprises alike. Users consistently praise its reliability, rich feature set, extensibility, and freedom from licensing costs. Its reputation for data integrity and correctness is a major reason it is trusted for critical systems.
At the same time, users acknowledge limitations for very large-scale analytics, particularly around automatic scaling and operational simplicity. Some organizations find PostgreSQL less suitable for high-frequency analytical queries on massive datasets without additional tooling or architectural enhancements.
Future Direction and Community Roadmap
PostgreSQL’s future is driven by an active global community focused on continuous improvement. Ongoing development emphasizes better performance on modern hardware, improved scalability for large datasets, enhanced security features, and more efficient query execution.
Community discussions and planned enhancements show a clear intent to make PostgreSQL more enterprise-ready for analytics and warehousing workloads. This steady evolution continues to narrow the gap between open-source databases and commercial data warehouse platforms.
Why PostgreSQL Is a Top Data Warehouse Software Option for 2026
PostgreSQL earns its place among the top data warehouse software options for 2026 due to its powerful SQL engine, extensibility, strong performance with complex queries, and zero licensing cost. While it requires hands-on management and thoughtful architecture to scale effectively, organizations that invest in PostgreSQL gain a flexible, transparent, and highly capable data platform that can support a wide range of analytical and data warehousing use cases.
9. Teradata Vantage

Teradata Vantage is widely recognized as one of the most powerful enterprise analytics and data warehouse platforms heading into 2026. It is designed to help large organizations manage, analyze, and activate massive volumes of data across hybrid and multi-cloud environments. Teradata Vantage is especially well suited for enterprises that require high performance, trusted AI, and consistent analytics across complex, distributed data landscapes.
The platform is positioned for organizations dealing with mission-critical workloads, advanced analytics, and long-term data strategies. Its ability to harmonize data at scale while supporting real-time and advanced analytical use cases makes it a strong contender among the top data warehouse software options for 2026.
Hybrid Multi-Cloud Architecture and Platform Design
Teradata Vantage is built as a cloud-native platform that can run seamlessly across public clouds and private infrastructure. Organizations can deploy it on major cloud environments or within their own data centers, allowing them to balance performance, compliance, and cost requirements.
A key architectural strength of Vantage is its multidimensional scalability. This means the platform can independently scale compute, storage, users, and workloads without performance degradation. Distributed processing ensures that complex analytical tasks are executed efficiently across large datasets, even in hybrid or multi-cloud configurations.
Architecture Capability Matrix
Architecture Component | Business Advantage
Hybrid and multi-cloud deployment | Flexibility across cloud and on-premises environments
Multidimensional scalability | Independent scaling of users, data, and workloads
Distributed processing engine | High performance on very large datasets
Cloud-native foundation | Future-ready enterprise architecture
Analytics Capabilities and Enterprise Features
Teradata Vantage provides a comprehensive set of analytics and data management capabilities within a single platform. It supports data modeling, transformation, integration, analytics, and reporting directly inside the platform, reducing the need to move data between systems.
The platform includes tools for workload management, monitoring, metadata management, and real-time analytics. It also offers in-platform data science and AI capabilities, allowing organizations to analyze data where it resides rather than exporting it to external tools. Prebuilt, industry-specific data models help enterprises accelerate time to insight.
Feature Coverage Overview
Capability Area | Strength Level
Enterprise data warehousing | Very strong
Advanced analytics and AI | Strong and integrated
Real-time analytics | Fully supported
Workload management | Enterprise-grade
Industry data models | Prebuilt and customizable
Performance and Scalability at Massive Scale
Performance is one of Teradata Vantage’s strongest differentiators. The platform is engineered to process extremely large datasets with minimal need for manual tuning or indexing. High parallelism enables fast query execution even as data volumes and concurrency increase.
Enterprises report faster production cycles and improved campaign execution due to Vantage’s ability to handle complex analytical workloads efficiently. Its performance is not tied to a single cloud provider, allowing organizations to optimize cost and throughput by leveraging hybrid and multi-cloud infrastructure.
Performance Snapshot
Metric | Typical Outcome
Query execution on large datasets | Fast and highly parallel
Index dependency | Minimal
Scalability impact | Stable at very large scale
Production workload throughput | High and consistent
Pricing Flexibility and Cost Considerations
Teradata Vantage offers flexible pricing models designed to align with different deployment and consumption patterns. By supporting hybrid and multi-cloud deployments, organizations can optimize costs by choosing the most appropriate infrastructure for each workload.
While detailed pricing varies by deployment and usage, Vantage is generally positioned for enterprise budgets. Its value is strongest for organizations that fully leverage its scalability, performance, and advanced analytics capabilities rather than smaller teams with lightweight data needs.
Cost and Suitability Matrix
Organization Type | Cost Fit Assessment
Large global enterprises | Strong fit
Data-intensive industries | Strong fit
Mid-sized organizations | Selective fit
Small analytics teams | Limited fit
Security, Governance, and Data Trust
Teradata Vantage includes enterprise-grade security and governance features designed to protect sensitive data and maintain trust at scale. Capabilities such as data masking help organizations control access to confidential information while enabling analytics across teams.
The broader Teradata ecosystem reflects a strong focus on security, compliance, and operational reliability. These capabilities are critical for enterprises operating in regulated industries or managing sensitive customer and operational data.
Ecosystem Integration and Connectivity
Teradata Vantage integrates with a wide range of data integration, ETL, and business intelligence tools. Extensive connectors and interoperability allow organizations to embed Vantage into existing data pipelines without disruption.
It works seamlessly with popular visualization and analytics tools, enabling business users to access insights without needing to understand the underlying data complexity. Industry-specific models and connectors further simplify integration in complex enterprise environments.
User Feedback and Market Perception
User feedback consistently highlights Teradata Vantage’s exceptional performance on large datasets, its scalability, and the quality of enterprise support. Many users describe it as fast, reliable, and well suited for demanding analytical workloads.
Reviewers also appreciate its ability to evolve with modern data requirements, including dynamic workload management and advanced analytics. Local AI capabilities that reduce data movement are frequently cited as a major advantage for performance and governance.
Strategic Roadmap and Future Direction
Teradata’s roadmap places strong emphasis on generative AI, trusted AI at scale, real-time data quality, and expanded collaboration capabilities. The platform is evolving to support more interactive analytics and broader access to data insights across the enterprise.
A key strategic goal is to help organizations transition toward data fabric architectures, where data is more connected, governed, and accessible. This direction positions Teradata Vantage as not just a data warehouse, but a foundational platform for enterprise-wide analytics and AI.
Why Teradata Vantage Is a Top Data Warehouse Choice for 2026
Teradata Vantage earns its place among the top data warehouse software options for 2026 due to its unmatched scalability, enterprise-grade performance, hybrid multi-cloud flexibility, and strong focus on trusted AI. While it is best suited for large and complex organizations, enterprises that operate at massive scale benefit from its ability to deliver fast, reliable, and actionable insights across diverse data environments.
10. SAP Datasphere
SAP Datasphere is positioned as one of the most important enterprise data warehousing and data management platforms to consider in 2026. It is designed to unify data integration, cataloging, semantic modeling, virtualization, and analytics across both SAP and non-SAP systems. As the strategic successor to SAP BW and SAP BW/4HANA, SAP Datasphere plays a central role in SAP’s long-term data and analytics strategy.
The platform is especially relevant for large enterprises that want to enable self-service analytics for business users while maintaining strong governance, semantic consistency, and enterprise-grade security. Its focus on business context, rather than raw data storage alone, differentiates it from many traditional cloud data warehouses.
Unified Architecture and Federated-First Design
SAP Datasphere is built as a multi-cloud, cloud-native service that can run across major hyperscalers. Its architecture is designed to connect data across distributed systems rather than forcing all data into a single physical repository. This federated-first approach allows organizations to access data where it already lives, reducing unnecessary data duplication and lowering operational complexity.
A key architectural concept within Datasphere is the use of governed workspaces called Spaces. These allow enterprises to combine central enterprise data, departmental data, and external data in a controlled and use-case-driven manner. This structure supports domain-based data ownership while maintaining enterprise-wide governance.
Architecture Capability Matrix
Architecture Element | Enterprise Benefit
Federated-first data access | Faster insights without heavy data movement
Multi-cloud deployment | Flexibility across cloud providers
Governed Spaces | Secure, domain-based data collaboration
Semantic modeling layer | Consistent business definitions across teams
Data Integration, Modeling, and Analytics Capabilities
SAP Datasphere is designed to act as a central business data layer rather than just a storage engine. It integrates data from SAP S/4HANA, SAP BW, and a wide range of third-party cloud and on-premises sources. Built-in replication options allow frequently used data to be cached locally for faster performance when needed.
The platform places strong emphasis on semantic modeling, enabling business-friendly data definitions that are reusable across analytics, planning, and reporting tools. This makes it easier for non-technical users to perform self-service analytics without needing deep knowledge of underlying data structures.
Feature Coverage Overview
Capability Area | Strength Level
Enterprise data integration | Very strong
Semantic modeling | Industry-leading
Data virtualization | Core platform capability
Self-service analytics enablement | Strong
Third-party data access | Extensive
Performance Characteristics and Data Agility
SAP Datasphere is optimized for data agility rather than raw query speed alone. By accessing data in place and minimizing large-scale data movement, the platform enables faster time-to-insight across complex and distributed data landscapes. This approach is particularly valuable for enterprises operating across multiple systems and geographies.
That said, performance can vary depending on query complexity, data source location, and virtualization depth. For highly complex analytical queries, replication into managed storage may be required to achieve optimal performance. This reflects a strategic trade-off that prioritizes flexibility and agility over brute-force processing.
Performance and Agility Snapshot
Metric | Typical Outcome
Time-to-insight | Fast for distributed data access
Query performance | Depends on virtualization depth
Data duplication | Significantly reduced
Operational agility | High
Pricing Structure and Cost Considerations
SAP Datasphere typically does not require an upfront setup fee, but it is often perceived as a premium-priced platform. Costs are higher compared to many standalone cloud data warehouses, especially for organizations that are new to the SAP ecosystem.
For enterprises already running SAP applications, the value proposition is stronger due to tight integration and reduced data engineering effort. For others, cost can be a deciding factor, particularly when advanced features and certifications are required.
Cost and Suitability Matrix
Organization Type | Cost Fit Assessment
Large SAP-centric enterprises | Strong fit
Mixed SAP and non-SAP environments | Good fit
Mid-sized organizations | Selective fit
Cost-sensitive teams | Limited fit
Security, Compliance, and Data Governance
Security and compliance are core strengths of SAP Datasphere. The platform includes encryption at rest, strict access controls, and built-in governance capabilities aligned with enterprise and regulatory requirements. It complies with a wide range of international security and compliance standards, making it suitable for regulated industries.
Integrated data cataloging and governance features allow organizations to manage metadata, data lineage, and access policies centrally. This supports trust, auditability, and regulatory compliance across large and complex data estates.
Ecosystem Integration and Partner Landscape
SAP Datasphere integrates seamlessly with SAP’s broader analytics and planning tools, forming a cohesive end-to-end data and analytics stack. It also supports integration with leading third-party data, AI, and governance platforms, allowing enterprises to extend functionality beyond the SAP ecosystem.
Multi-source connectivity enables organizations to unify analytics across ERP, CRM, cloud platforms, and external data providers. This openness is critical for enterprises operating hybrid and multi-cloud data architectures.
User Feedback and Market Perception
User feedback consistently highlights SAP Datasphere’s strength in unified data access, semantic modeling, and integration across SAP and non-SAP systems. Many users value its scalability, flexibility, and ability to serve as both an ETL and analytics enablement platform.
Common challenges include a learning curve for new users, high certification costs, and perceived gaps in performance and ecosystem maturity compared to some competitors. Some users also note limitations in data export to external systems and mixed results in AI feature maturity. Despite this, overall satisfaction remains solid among enterprise users.
Strategic Roadmap and Future Outlook
SAP’s roadmap for Datasphere shows strong momentum and long-term commitment. Recent and planned enhancements focus on AI-driven data management, embedded planning, richer data catalogs, and expanded real-time replication. The move toward broad multi-cloud availability significantly increases platform flexibility.
A key strategic direction is the evolution toward a business data fabric, where curated data products, knowledge graphs, and AI-driven insights are delivered directly to business users. This approach aims to close previous functionality gaps and strengthen Datasphere’s role as an enterprise data foundation.
Why SAP Datasphere Is a Top Data Warehouse Software Choice for 2026
SAP Datasphere earns its place among the top data warehouse software options for 2026 due to its unified approach to data integration, virtualization, semantic modeling, and governance. While it is best suited for large enterprises and SAP-centric environments, organizations that prioritize business-context-driven analytics, strong governance, and multi-cloud flexibility will find it to be a powerful and future-ready data platform.
The Rapid Evolution of Data Warehousing Heading Into 2026
The global data warehousing landscape is experiencing a profound shift as organizations move away from traditional, on-premises systems toward cloud-native, highly scalable data platforms. By 2026, data warehouses are no longer viewed as static storage systems, but as intelligent, cloud-powered foundations for analytics, artificial intelligence, and real-time decision-making across the enterprise.
Market growth reflects this transformation clearly. Cloud-based data warehouse adoption continues to accelerate as businesses generate exponentially larger volumes of data from digital platforms, connected devices, applications, and customer interactions. At the same time, organizations are under increasing pressure to extract insights faster, govern data more effectively, and support advanced analytics use cases without the operational burden of legacy infrastructure.
Market Growth and Economic Outlook
The cloud data warehouse market is expanding at an exceptional pace, driven by widespread cloud adoption, the explosion of big data, and growing reliance on analytics for competitive advantage. Data Warehouse as a Service has emerged as a critical delivery model, allowing enterprises to consume data infrastructure on demand without managing hardware or complex deployments.
North America currently leads global adoption due to its mature cloud ecosystem, advanced analytics culture, and strong presence of hyperscale cloud providers. However, rapid growth is also being observed across Europe, Asia-Pacific, and emerging digital economies as cloud analytics becomes a global standard.
Global Data Warehouse Market Growth Overview
Market Segment | Market Size 2024 (USD Billion) | Market Size 2025 (USD Billion) | Market Size 2034 (USD Billion) | CAGR 2025–2034
Cloud Data Warehouse | 30.89 | 36.31 | 155.66 | 17.55%
Data Warehouse as a Service | 6.85 | 8.13 | 37.84 | 18.64%
Enterprise Data Warehouse | 3.03 | 4.51 | 45.16 | 23.10%
Key Trends Shaping Data Warehousing in 2026
Modern data warehousing platforms are increasingly cloud-native, AI-enabled, and designed for massive scale. Enterprises now expect data warehouses to support structured, semi-structured, and unstructured data within a single environment. Real-time analytics, automated optimization, and native machine learning capabilities are becoming standard expectations rather than optional features.
Another defining shift is the convergence of data warehouses, data lakes, and analytics platforms. Many leading solutions now adopt lakehouse or hybrid architectures, allowing organizations to unify analytics, data science, and operational reporting on a single data foundation. Governance, security, and compliance are also being embedded directly into platforms to support regulatory and enterprise data requirements at scale.
What Enterprises Look for in the Best Data Warehouse Software
As organizations evaluate the top data warehouse software to use in 2026, selection criteria have expanded well beyond basic performance. Decision-makers now prioritize platforms that deliver scalability, cost efficiency, flexibility across clouds, and strong ecosystem integration. Ease of use for business teams, automation for data engineering, and AI-driven insights are equally important.
Key Evaluation Criteria | Strategic Importance in 2026
Cloud-native scalability | Supports rapid data growth without re-architecture
AI and machine learning integration | Enables predictive and intelligent analytics
Multi-data type support | Handles structured and unstructured data seamlessly
Governance and security | Ensures compliance and data trust at scale
Ecosystem connectivity | Integrates with BI, AI, and operational tools
Why 2026 Marks a Defining Moment for Data Warehousing
By 2026, data warehouses have evolved into strategic intelligence platforms rather than back-end systems. Organizations that invest in modern data warehouse software gain faster insights, improved data quality, and the ability to operationalize analytics across departments. Those that rely on outdated architectures risk slower decision-making, higher costs, and limited scalability.
The top data warehouse software solutions in 2026 reflect this evolution. They are built for cloud environments, optimized for AI-driven analytics, and designed to empower both technical teams and business users. Understanding this broader market context is essential before evaluating individual platforms, as it highlights why data warehousing is now central to digital transformation strategies worldwide.
Comparative Analysis of Leading Data Warehouse Platforms for 2026
As organizations evaluate the top data warehouse software to use in 2026, comparative, data-driven analysis becomes essential. While most modern platforms now share core capabilities such as cloud scalability, parallel processing, and advanced analytics, they differ significantly in performance focus, architectural priorities, and optimization strategies. Understanding these differences helps enterprises select the platform that best aligns with their data volume, workload complexity, and analytics goals.
Performance as a Strategic Differentiator
Performance remains one of the most critical decision factors in data warehousing. Faster query execution directly impacts business agility, enabling real-time insights, responsive dashboards, and efficient data pipelines. Although standardized, independently verified benchmarks are not consistently available across all vendors for the same time period, reported performance metrics and benchmark claims still provide valuable directional insight.
It is important to note that performance results often vary depending on data size, query type, concurrency levels, and system configuration. As a result, performance benchmarks should be viewed as indicators of potential capability rather than guaranteed outcomes for every environment.
Comparative Performance Snapshot Across Leading Platforms
Product | Reported Benchmark Indicator | Relative Speed Claims | Practical Query Performance Summary
Google BigQuery | No public TPC-DS score | Up to 90% faster than traditional systems | Processes petabytes in seconds with sub-second responses
Snowflake | No public TPC-DS score | Continuous internal optimization gains | Tens of millions of rows processed in seconds
Amazon Redshift | TPC-DS commonly referenced | Up to 7x better throughput claims | High-speed analytics at petabyte scale
Microsoft Azure Synapse Analytics | Spark Native Engine benchmarks | Up to 4x faster than open-source Spark | Seconds-level analytics on large warehouses
Oracle Autonomous Data Warehouse | No public TPC-DS score | Rapid provisioning and auto-scaling | Strong performance with reduced operational overhead
Databricks SQL | 32,941,245 QphDS at 100TB | 2.7x faster than Snowflake for data loading | Industry-leading throughput for analytics and ML
IBM Db2 Warehouse | No public TPC-DS score | Strong real-time query responsiveness | Fast ingest and consistent performance
PostgreSQL | No public TPC-DS score | 1.6x faster than MySQL for complex queries | Efficient complex analytics with tuning
Teradata Vantage | No public TPC-DS score | High parallelism on large datasets | Enterprise-scale performance with minimal tuning
SAP Datasphere | No public TPC-DS score | Focus on agility over raw speed | Faster insights through data virtualization
Performance Leadership Insights
Among the platforms compared, Databricks SQL demonstrates the strongest publicly stated benchmark leadership, holding a record-setting TPC-DS result at large scale and showing significant gains in data loading and analytical throughput. This positions it well for organizations running complex, high-volume analytical and machine learning workloads.
Snowflake, while challenged in specific benchmark comparisons, emphasizes steady and automatic performance improvements over time. Its focus on continuous optimization provides predictable gains without requiring user intervention, which appeals to teams prioritizing operational simplicity.
Google BigQuery consistently highlights its ability to scan massive datasets extremely quickly, often emphasizing dramatic reductions in query time compared to traditional systems. This makes it especially suitable for ad hoc analytics on very large datasets.
Azure Synapse Analytics shows notable performance improvements when operating at true enterprise scale, particularly with large datasets and Spark-based analytics. Its performance advantages are most visible in environments exceeding one terabyte of data.
PostgreSQL, as an open-source option, demonstrates that commercial licensing is not a prerequisite for strong performance. With each release delivering measurable improvements, it remains competitive for complex analytical queries when properly optimized.
Interpreting Benchmark Data Responsibly
When comparing these performance claims, several caveats must be considered. Benchmark versions, data sizes, and testing methodologies differ across vendors, making direct comparisons imperfect. Some results may be optimized specifically for benchmark scenarios rather than real-world workloads.
Additionally, real-world performance depends heavily on workload design, query patterns, data modeling, and infrastructure configuration. Factors such as concurrency, data freshness requirements, and integration with analytics tools can significantly influence outcomes.
Key Performance Evaluation Considerations
Evaluation Factor | Why It Matters in 2026
Data volume scale | Performance varies significantly at different data sizes
Query complexity | Simple scans and complex joins behave differently
Concurrency requirements | Multi-user environments stress systems differently
Automation and tuning | Reduces operational effort and performance risk
Real-time vs batch needs | Determines suitability for operational analytics
Why Comparative Analysis Matters for 2026 Decisions
As data warehouses evolve into intelligence platforms, performance alone is no longer the only deciding factor. However, it remains a foundational requirement that directly affects user adoption, analytics velocity, and cost efficiency. The top data warehouse software solutions for 2026 balance raw performance with scalability, governance, automation, and ecosystem integration.
A comparative, data-driven approach allows organizations to align platform strengths with business priorities. By understanding where each solution excels and where trade-offs exist, enterprises can make informed decisions that support long-term analytics, AI, and data-driven growth strategies.
Cost Efficiency and Pricing Considerations Across Leading Data Warehouse Platforms
When evaluating the Top 10 Best Data Warehouse Software to Use in 2026, cost efficiency plays a decisive role alongside performance and scalability. Data warehouse pricing models have become increasingly complex, often combining compute usage, storage consumption, and additional service charges. As a result, understanding total cost of ownership is more important than simply comparing headline prices.
Modern platforms generally promote flexibility through usage-based pricing, but this flexibility can also introduce unpredictability. Organizations must carefully align pricing structures with their workload patterns, query frequency, data growth, and internal operational capabilities to avoid unexpected cost escalation.
Overview of Pricing Models and Cost Structures
Product | Pricing Model | Storage Cost Approach | Compute Cost Approach | Key Cost Strengths and Risks
Google BigQuery | On-demand and flat-rate | Tiered storage with lower rates for inactive data | Charged per data scanned or reserved slots | Low entry cost and serverless model reduce admin overhead, but heavy querying can lead to unpredictable spend
Snowflake | Pay-as-you-go with per-second billing | Usage-based with no backup charges | Credits consumed by virtual warehouses | Fine-grained cost control when monitored, but costs rise quickly with sustained workloads
Amazon Redshift | On-demand, reserved capacity, managed storage | Lower-cost managed storage options | Hourly pricing based on node types | Long-term savings with reservations, but non-serverless model increases management overhead
Microsoft Azure Synapse Analytics | Separate billing for storage and compute | Fixed monthly storage pricing | Scalable compute units billed hourly | Flexible scaling and reservation discounts, but complex for smaller or inconsistent workloads
Oracle Autonomous Data Warehouse | Usage-based with automated scaling | Bundled within platform pricing | Bundled within platform pricing | Automation reduces operational cost, but licensing can be expensive for non-Oracle-centric teams
Databricks SQL | Usage-based with platform units plus cloud compute | Depends on underlying cloud storage | Charged per platform unit plus infrastructure | Strong value for advanced analytics, but cost modeling can be difficult for continuous pipelines
IBM Db2 Warehouse | Tiered plans with elastic compute | Included in platform tiers | Instance-based hourly pricing | Predictable scaling options, but premium tiers require higher upfront investment
PostgreSQL | Open-source software | Infrastructure-dependent | Infrastructure-dependent | No licensing fees, but operational and staffing costs can raise total ownership cost
Teradata Vantage | Flexible enterprise pricing | Varies by deployment model | Varies by deployment model | Optimized for large enterprises, but cost transparency is limited for smaller teams
SAP Datasphere | Subscription-based with no setup fee | Bundled within subscription | Bundled within subscription | Simplified onboarding, but widely perceived as expensive relative to alternatives
Key Cost Efficiency Insights
Open-source platforms such as PostgreSQL often appear to be the most cost-effective at first glance due to the absence of licensing fees. However, organizations remain responsible for infrastructure provisioning, security hardening, upgrades, performance tuning, and support. For teams without strong database expertise, these operational costs can outweigh the savings from free software.
Cloud-native platforms emphasize consumption-based pricing to reduce upfront investment. While this model supports rapid experimentation and elastic scaling, it also introduces cost variability. Platforms that charge per query, per data scanned, or per compute unit can become expensive when workloads scale or query patterns are inefficient.
Enterprise-focused solutions such as Oracle Autonomous Data Warehouse, Teradata Vantage, and SAP Datasphere often justify higher pricing through automation, governance, and enterprise-grade reliability. These platforms can reduce operational burden but may exceed the budget constraints of smaller teams or analytics-light organizations.
Cost Predictability Versus Flexibility Matrix
Cost Dimension | Predictable Cost Platforms | Highly Flexible but Variable Cost Platforms
Upfront transparency | PostgreSQL, reserved cloud plans | Usage-based serverless platforms
Operational overhead | Autonomous and managed services | Self-managed or semi-managed systems
Scalability cost control | Reserved or tiered pricing | Pay-per-query or per-unit billing
Best fit use case | Stable, long-term workloads | Dynamic, experimental, or bursty workloads
Hidden Costs and Total Cost of Ownership
A recurring theme across all platforms is the gap between advertised pricing and real-world total cost of ownership. Factors such as data egress, concurrency scaling, idle compute, monitoring tools, and staff expertise can significantly affect long-term spend.
Pricing complexity also makes direct vendor comparison challenging. Units such as credits, slots, vCores, platform units, or data scanned require careful translation into expected monthly and annual costs. Without workload simulation or pilot testing, organizations risk underestimating future expenses.
Why Cost Analysis Matters for 2026 Decisions
As data warehouses evolve into central intelligence platforms supporting analytics, AI, and real-time operations, cost efficiency becomes a strategic concern rather than a procurement detail. The best data warehouse software in 2026 is not necessarily the cheapest option, but the one that delivers the highest value relative to performance, scalability, governance, and operational effort.
A structured cost analysis allows organizations to align platform choice with business maturity, data complexity, and growth plans. By understanding both visible and hidden costs, decision-makers can select a data warehouse solution that supports long-term analytics success without compromising financial sustainability.
Feature Set and Ecosystem Integration Across the Top Data Warehouse Platforms for 2026
Modern data warehouse software has evolved far beyond basic data storage. In 2026, leading platforms are expected to deliver advanced analytics, built-in AI and machine learning, real-time processing, and seamless integration across a wide enterprise technology ecosystem. While core capabilities are increasingly converging, each platform differentiates itself through architectural design, integration philosophy, and ecosystem depth.
The following feature and integration overview highlights how the top data warehouse solutions compare and why they are considered among the best choices for enterprise analytics in 2026.
Core Architecture and Feature Comparison
Product | Architecture Type | Core Feature Strengths | Cloud Model | Key Integration Focus
Google BigQuery | Serverless, decoupled storage and compute, columnar | Built-in machine learning, geospatial analytics, real-time querying, automated administration | Cloud-native | Deep integration with analytics, ML, and visualization tools
Snowflake | Multi-cluster shared architecture, MPP | SQL and JSON analytics, auto-scaling, secure data sharing, data lake integration | Cloud-agnostic | Strong ETL, BI, and data sharing ecosystem
Amazon Redshift | Massively parallel processing, columnar storage | Concurrency scaling, predictive analytics, real-time insights | Cloud-native | Tight integration with cloud data, streaming, and AI services
Microsoft Azure Synapse Analytics | Unified analytics platform, MPP | Big data and data warehousing unification, workload isolation, result caching | Cloud-native | Seamless integration across analytics, identity, and ML services
Oracle Autonomous Data Warehouse | AI-driven autonomous platform | Self-tuning, self-scaling, self-patching, in-database analytics | Hybrid cloud | Strong automation with analytics and integration services
Databricks SQL | Lakehouse architecture, Spark-based, serverless SQL | Machine learning workflows, ACID reliability, real-time and batch processing | Cloud-native | Deep ML, data engineering, and analytics convergence
IBM Db2 Warehouse | MPP, in-memory columnar, containerized | Built-in ML, geospatial analytics, federated queries, hybrid portability | Hybrid cloud | Strong enterprise and hybrid analytics tooling
PostgreSQL | Open-source object-relational | Advanced SQL, JSON support, extensibility, geospatial analytics | Infrastructure-agnostic | Broad compatibility with ETL and BI tools
Teradata Vantage | Hybrid multi-cloud, distributed processing | Multidimensional scalability, in-platform analytics, real-time processing | Hybrid multi-cloud | Enterprise-grade analytics and industry data models
SAP Datasphere | Unified data fabric | Data integration, semantic modeling, virtualization, governed workspaces | Multi-cloud | Business-context-driven analytics across SAP and non-SAP systems
Azure SQL Database | Relational with MPP | Autoscaling, intelligent tuning, cross-database queries, encryption | Cloud-native | Tight integration with analytics, identity, and data lake services
Ecosystem Integration Patterns and Strategic Differentiation
Across all leading platforms, advanced analytics, AI capabilities, and support for both structured and unstructured data are now standard expectations. The key differentiator lies in how each vendor integrates these capabilities into a broader enterprise ecosystem.
Cloud providers such as Google, AWS, and Microsoft offer deeply integrated environments where data warehousing, analytics, AI, and application services work seamlessly together. This is particularly advantageous for organizations already standardized on a specific cloud provider, as it reduces integration friction and operational complexity.
Snowflake stands out for its cloud-agnostic architecture, allowing organizations to run the same data platform across multiple cloud providers. This flexibility appeals to enterprises seeking portability, vendor neutrality, and multi-cloud resilience.
Databricks emphasizes the lakehouse model, merging data warehousing and data lake functionality into a single platform. Its strength in machine learning and data science workflows makes it especially suitable for organizations where analytics and AI are tightly intertwined.
Oracle Autonomous Data Warehouse differentiates through heavy automation. By embedding AI-driven tuning, scaling, and patching directly into the platform, it reduces operational overhead and appeals to enterprises prioritizing hands-off management and reliability.
IBM Db2 Warehouse focuses on hybrid portability and enterprise-grade stability, particularly for organizations operating across on-premises and cloud environments. Its Kubernetes-based deployment model supports consistent operations across infrastructure types.
PostgreSQL remains unique as an open-source option, offering unmatched flexibility and extensibility. While it requires more hands-on management, it allows organizations to tailor analytics environments without licensing constraints.
SAP Datasphere is evolving toward a business data fabric, prioritizing semantic consistency, data virtualization, and business-user accessibility. This approach is especially valuable for enterprises that need governed, context-rich analytics across complex system landscapes.
How Feature Convergence Shapes 2026 Decisions
The data warehouse market in 2026 reflects strong convergence in core capabilities, including AI integration, real-time analytics, and scalable performance. However, platforms continue to differentiate through architectural philosophy, ecosystem alignment, and operational approach.
Strategic Focus | Platforms That Excel
Deep cloud ecosystem integration | BigQuery, Redshift, Azure Synapse
Multi-cloud flexibility | Snowflake, Teradata Vantage
AI and machine learning convergence | Databricks SQL, Oracle Autonomous Data Warehouse
Hybrid and enterprise portability | IBM Db2 Warehouse, Teradata Vantage
Open-source flexibility | PostgreSQL
Business-context-driven analytics | SAP Datasphere
Why Feature and Ecosystem Fit Matters in 2026
Choosing the best data warehouse software in 2026 is no longer about selecting the platform with the most features. Instead, success depends on selecting a platform whose architecture and ecosystem align with enterprise strategy, data maturity, and long-term analytics goals.
Organizations that understand these feature and integration differences are better positioned to build scalable, future-ready data platforms. The top data warehouse solutions in 2026 succeed not only by storing and querying data efficiently, but by embedding analytics, AI, and governance into the heart of enterprise decision-making.
Security and Compliance Standards Across the Top Data Warehouse Platforms for 2026
As organizations evaluate the Top 10 Best Data Warehouse Software to Use in 2026, security and regulatory compliance are no longer optional considerations. They are fundamental requirements. Modern data warehouses operate at the core of enterprise decision-making, often handling sensitive customer, financial, and operational data. As a result, leading platforms have invested heavily in advanced security controls, encryption, access management, and global compliance certifications.
Today’s market shows strong convergence around baseline regulatory standards. However, differentiation increasingly comes from how deeply security and governance are embedded into daily data operations rather than from certifications alone.
Enterprise Security Capabilities Across Leading Platforms
Product | Core Security Capabilities | Compliance Coverage
Google BigQuery | Encryption at rest and in transit, fine-grained dataset and column permissions, conditional access policies, row and column security, audit logging and monitoring | GDPR, HIPAA, PCI DSS, SOC 2, ISO 27001
Snowflake | End-to-end encryption, multi-factor authentication, role-based access control, AI-based threat monitoring, credential leak detection | GDPR, HIPAA, PCI DSS, SOC 2, ISO 27001, FedRAMP, DoD impact levels
Amazon Redshift | Encryption by default, secure network isolation, enforced secure connections, granular access controls, row and column permissions | SOC, PCI DSS, HIPAA, GDPR, FedRAMP
Microsoft Azure Synapse Analytics | Always-on encryption, dynamic data masking, granular schema and column permissions, row and column security, governance integration | HIPAA, GDPR, ISO 27001, SOC 1, SOC 2, SOC 3, FedRAMP
Oracle Autonomous Data Warehouse | Transparent encryption, key management, privileged user controls, automated auditing, data masking and redaction, immutable backups | Broad international and industry-specific compliance coverage
Databricks SQL | Unified governance layer, field-level encryption, schema enforcement, data lineage, ACID reliability, time travel | SOC 1, SOC 2, SOC 3, GDPR, HIPAA, ISO 27001, PCI DSS, FedRAMP
IBM Db2 Warehouse | End-to-end encryption, secure communication protocols, certified cryptographic providers, access controls | HIPAA, ISO 27001 family, SOC 2 Type II, GDPR-related frameworks
PostgreSQL | ACID compliance, role-based permissions, secure storage, strong transaction controls | SOC 2 Type II via managed providers, HIPAA with additional agreements
Teradata Vantage | Data masking and access controls within enterprise analytics workflows | ISO 27001 and SOC 2 through ecosystem integrations
SAP Datasphere | Encryption at rest, enterprise-grade access controls, governed data environments | ISO 27001, ISO 22301, SOC 1, SOC 2, CSA STAR, EU Cloud Code of Conduct
Azure SQL Database | Always-on encryption, identity-based access control, secure network isolation | GDPR, HIPAA, ISO 27001
Baseline Compliance Is Now a Given
Across nearly all leading platforms, compliance with major regulations such as GDPR, HIPAA, SOC 2, and ISO 27001 has become a standard expectation rather than a differentiator. Enterprises evaluating data warehouse software in 2026 can safely assume that baseline regulatory requirements will be met by most top-tier vendors.
This shift reflects the maturity of the market. Vendors now treat regulatory compliance as table stakes, ensuring that platforms are suitable for use in regulated industries such as finance, healthcare, government, and global commerce.
The Shift From Compliance to Data Trust
While compliance certifications remain essential, the strategic focus has moved toward building comprehensive data trust frameworks. Organizations increasingly require platforms that go beyond static security controls and support continuous governance across the data lifecycle.
Advanced governance capabilities such as metadata management, automated data classification, lineage tracking, and policy-driven access controls are becoming critical. These features help organizations understand where data comes from, how it is used, and who can access it, all while maintaining auditability.
Governance Maturity Comparison
Governance Capability | Basic Requirement | Advanced Differentiator
Encryption and access control | Expected across all platforms | Automated and policy-driven enforcement
Compliance certifications | Standard requirement | Continuous compliance monitoring
Audit logging | Widely available | Real-time monitoring and anomaly detection
Data lineage and cataloging | Emerging standard | Fully integrated governance layer
Security Strategy Considerations for 2026
As data volumes grow and analytics becomes more decentralized, security strategies must scale without slowing innovation. Platforms that embed governance directly into analytics workflows reduce friction between compliance teams and business users.
Cloud-native platforms often excel at automated security enforcement, while hybrid and enterprise-focused platforms emphasize control and customization. Open-source options offer flexibility but place greater responsibility on internal teams to design and maintain secure environments.
Why Security and Compliance Matter More Than Ever
In 2026, data warehouses are no longer passive repositories. They are active intelligence platforms supporting AI, real-time analytics, and cross-functional decision-making. This increased importance raises the stakes for security, privacy, and regulatory adherence.
The best data warehouse software in 2026 combines strong baseline compliance with advanced governance automation. Organizations that prioritize data trust alongside performance and cost efficiency will be better positioned to scale analytics responsibly, meet regulatory demands, and maintain confidence in their data-driven strategies.
As organizations evaluate the Top 10 Best Data Warehouse Software to Use in 2026, security and regulatory compliance are no longer optional considerations. They are fundamental requirements. Modern data warehouses operate at the core of enterprise decision-making, often handling sensitive customer, financial, and operational data. As a result, leading platforms have invested heavily in advanced security controls, encryption, access management, and global compliance certifications.
Today’s market shows strong convergence around baseline regulatory standards. However, differentiation increasingly comes from how deeply security and governance are embedded into daily data operations rather than from certifications alone.
Enterprise Security Capabilities Across Leading Platforms
Product | Core Security Capabilities | Compliance Coverage
Google BigQuery | Encryption at rest and in transit, fine-grained dataset and column permissions, conditional access policies, row and column security, audit logging and monitoring | GDPR, HIPAA, PCI DSS, SOC 2, ISO 27001
Snowflake | End-to-end encryption, multi-factor authentication, role-based access control, AI-based threat monitoring, credential leak detection | GDPR, HIPAA, PCI DSS, SOC 2, ISO 27001, FedRAMP, DoD impact levels
Amazon Redshift | Encryption by default, secure network isolation, enforced secure connections, granular access controls, row and column permissions | SOC, PCI DSS, HIPAA, GDPR, FedRAMP
Microsoft Azure Synapse Analytics | Always-on encryption, dynamic data masking, granular schema and column permissions, row and column security, governance integration | HIPAA, GDPR, ISO 27001, SOC 1, SOC 2, SOC 3, FedRAMP
Oracle Autonomous Data Warehouse | Transparent encryption, key management, privileged user controls, automated auditing, data masking and redaction, immutable backups | Broad international and industry-specific compliance coverage
Databricks SQL | Unified governance layer, field-level encryption, schema enforcement, data lineage, ACID reliability, time travel | SOC 1, SOC 2, SOC 3, GDPR, HIPAA, ISO 27001, PCI DSS, FedRAMP
IBM Db2 Warehouse | End-to-end encryption, secure communication protocols, certified cryptographic providers, access controls | HIPAA, ISO 27001 family, SOC 2 Type II, GDPR-related frameworks
PostgreSQL | ACID compliance, role-based permissions, secure storage, strong transaction controls | SOC 2 Type II via managed providers, HIPAA with additional agreements
Teradata Vantage | Data masking and access controls within enterprise analytics workflows | ISO 27001 and SOC 2 through ecosystem integrations
SAP Datasphere | Encryption at rest, enterprise-grade access controls, governed data environments | ISO 27001, ISO 22301, SOC 1, SOC 2, CSA STAR, EU Cloud Code of Conduct
Azure SQL Database | Always-on encryption, identity-based access control, secure network isolation | GDPR, HIPAA, ISO 27001
Baseline Compliance Is Now a Given
Across nearly all leading platforms, compliance with major regulations such as GDPR, HIPAA, SOC 2, and ISO 27001 has become a standard expectation rather than a differentiator. Enterprises evaluating data warehouse software in 2026 can safely assume that baseline regulatory requirements will be met by most top-tier vendors.
This shift reflects the maturity of the market. Vendors now treat regulatory compliance as table stakes, ensuring that platforms are suitable for use in regulated industries such as finance, healthcare, government, and global commerce.
The Shift From Compliance to Data Trust
While compliance certifications remain essential, the strategic focus has moved toward building comprehensive data trust frameworks. Organizations increasingly require platforms that go beyond static security controls and support continuous governance across the data lifecycle.
Advanced governance capabilities such as metadata management, automated data classification, lineage tracking, and policy-driven access controls are becoming critical. These features help organizations understand where data comes from, how it is used, and who can access it, all while maintaining auditability.
Governance Maturity Comparison
Governance Capability | Basic Requirement | Advanced Differentiator
Encryption and access control | Expected across all platforms | Automated and policy-driven enforcement
Compliance certifications | Standard requirement | Continuous compliance monitoring
Audit logging | Widely available | Real-time monitoring and anomaly detection
Data lineage and cataloging | Emerging standard | Fully integrated governance layer
Security Strategy Considerations for 2026
As data volumes grow and analytics becomes more decentralized, security strategies must scale without slowing innovation. Platforms that embed governance directly into analytics workflows reduce friction between compliance teams and business users.
Cloud-native platforms often excel at automated security enforcement, while hybrid and enterprise-focused platforms emphasize control and customization. Open-source options offer flexibility but place greater responsibility on internal teams to design and maintain secure environments.
Why Security and Compliance Matter More Than Ever
In 2026, data warehouses are no longer passive repositories. They are active intelligence platforms supporting AI, real-time analytics, and cross-functional decision-making. This increased importance raises the stakes for security, privacy, and regulatory adherence.
The best data warehouse software in 2026 combines strong baseline compliance with advanced governance automation. Organizations that prioritize data trust alongside performance and cost efficiency will be better positioned to scale analytics responsibly, meet regulatory demands, and maintain confidence in their data-driven strategies.
Key Trends Defining Data Warehousing in 2026
The data warehousing market entering 2026 is shaped by a set of powerful and interconnected trends that are redefining how organizations store, govern, analyze, and activate data. Modern data warehouses are no longer passive repositories. They are evolving into intelligent, automated, and highly adaptable platforms that sit at the core of enterprise analytics, AI, and decision-making. Understanding these trends is essential for evaluating the Top 10 Best Data Warehouse Software to Use in 2026.
Generative AI and Autonomous Data Platforms
Generative AI is rapidly transforming how data warehouses are managed and used. In 2026, AI is no longer limited to analytics and forecasting. It is now deeply embedded in core data management functions such as data ingestion, cleansing, transformation, governance, security, and performance optimization.
Leading platforms are moving toward autonomous operation, where AI continuously tunes queries, scales resources, applies patches, enforces governance rules, and detects anomalies without manual intervention. This shift significantly reduces the operational burden traditionally placed on database administrators and data engineers.
Examples across the market illustrate this transition clearly. Google BigQuery is evolving into a data-to-AI platform with built-in intelligence. Oracle Autonomous Data Warehouse already uses AI for self-tuning, self-scaling, and self-patching. IBM Db2 Warehouse incorporates AI-driven database management capabilities. Microsoft SQL Server is integrating AI directly into the database engine for intelligent search and optimization.
This trend signals a long-term shift where AI increasingly replaces manual database administration. As a result, data teams can focus more on delivering insights and less on maintaining infrastructure.
Autonomous Capabilities Impact Overview
Autonomous Capability | Business Impact
AI-driven tuning and scaling | Faster performance with minimal manual effort
Automated governance and security | Reduced risk and improved compliance
Natural language data interaction | Easier access for non-technical users
Anomaly and pattern detection | Proactive issue identification
The Rise of the Lakehouse Architecture
The lakehouse architecture has emerged as one of the most influential structural shifts in modern data warehousing. This approach combines the performance, governance, and reliability of data warehouses with the flexibility and scale of data lakes. By unifying these traditionally separate systems, organizations can analyze structured and unstructured data on a single platform.
Databricks pioneered the lakehouse model, enabling analytics and machine learning directly on open data formats. Microsoft Fabric extends this concept by offering a lake-centric analytics experience built on Azure Synapse. Oracle’s platform provides a strong foundation for lakehouse deployments, while Snowflake supports lakehouse-style patterns through external table and data lake integrations.
This widespread adoption reflects a shared industry understanding that data silos are no longer acceptable. Organizations need a unified data layer to support advanced analytics, AI, and machine learning at scale.
Lakehouse Benefits Compared to Traditional Architectures
Architecture Model | Key Limitation | Lakehouse Advantage
Separate data lake and warehouse | Data duplication and silos | Unified analytics on one data layer
Warehouse-only model | Limited unstructured data support | Native support for diverse data types
Lake-only model | Weak governance and performance | Strong governance with high performance
Real-Time Data Processing and Streaming Analytics
In 2026, real-time analytics is no longer a niche requirement. It is a core expectation. Businesses increasingly rely on instant insights to detect fraud, optimize operations, personalize customer experiences, and respond to market changes as they happen.
All major data warehouse platforms are investing heavily in streaming ingestion and near real-time query capabilities. Google BigQuery supports real-time streaming analytics. Amazon Redshift can ingest data at very high speeds for near real-time use cases. Microsoft Azure Synapse Analytics supports real-time data streaming and analytics. Oracle Autonomous Data Warehouse delivers real-time insights using built-in analytics. Databricks is architected to handle real-time execution alongside batch workloads.
This shift represents a fundamental move away from traditional batch-only processing. Streaming analytics is becoming essential for organizations that compete on speed and responsiveness.
Real-Time Analytics Use Case Alignment
Use Case | Real-Time Requirement Level
Fraud detection | Critical
Customer personalization | High
Operational monitoring | High
Strategic reporting | Moderate
The Evolution of Data Governance, Security, and Trust
By 2026, data governance has evolved from a compliance-focused function into a strategic enabler of data trust. While encryption, access controls, and compliance certifications are now standard across leading platforms, organizations are demanding more advanced governance capabilities.
Modern data warehouses are expected to provide automated policy enforcement, active metadata management, data cataloging, classification, lineage tracking, and impact analysis. The goal is not only to protect data, but also to ensure that it is reliable, discoverable, and usable.
Industry analysts emphasize that compliance alone is no longer sufficient. Data quality, usability, and transparency are now equally important. This shift reflects the growing recognition that trusted data is essential for AI-driven decision-making and regulatory confidence.
Governance Maturity Comparison
Governance Focus | Traditional Approach | Modern Approach
Compliance | Certification-driven | Continuous and automated
Security | Perimeter-based | Embedded and policy-driven
Data quality | Manual checks | Automated monitoring
Data discovery | Limited | Catalog-driven and searchable
Multi-Cloud and Hybrid Deployment Strategies
Multi-cloud and hybrid deployment models have become a defining characteristic of enterprise data strategies in 2026. Organizations are moving away from single-cloud dependency to improve resilience, avoid vendor lock-in, meet data sovereignty requirements, and optimize costs.
Several leading platforms reflect this shift clearly. Snowflake operates across multiple cloud providers with a consistent experience. Oracle supports robust hybrid deployments. IBM Db2 Warehouse offers Kubernetes-based portability across environments. SAP Business Data Cloud is expanding availability across major hyperscalers. Teradata Vantage is explicitly designed for hybrid multi-cloud deployments.
This trend indicates that future-proof data warehouse software must prioritize interoperability and flexible deployment. Enterprises increasingly expect to run analytics workloads wherever it makes the most business sense.
Deployment Strategy Comparison
Deployment Model | Primary Advantage
Single cloud | Simplicity and deep integration
Multi-cloud | Flexibility and vendor independence
Hybrid cloud | Data sovereignty and workload optimization
Why These Trends Matter for Choosing Data Warehouse Software in 2026
The Top 10 Best Data Warehouse Software to Use in 2026 reflect these trends in different ways, but all are shaped by them. AI-driven automation, lakehouse architectures, real-time analytics, advanced governance, and multi-cloud flexibility are no longer optional enhancements. They define the baseline expectations for modern data platforms.
Organizations that align their platform choices with these trends will be better positioned to scale analytics, adopt AI responsibly, and maintain trust in their data. Those that ignore them risk building systems that are rigid, costly, and unable to support future data-driven initiatives.
Strategic Recommendations
The data warehousing market heading into 2026 is fast-moving, competitive, and shaped by exponential data growth, the demand for real-time intelligence, and the rapid advancement of artificial intelligence. Modern data warehouse platforms are no longer simple storage layers. They are evolving into full-scale data intelligence systems that support analytics, AI, governance, and enterprise-wide decision-making.
A strategic selection approach is essential. Organizations must evaluate platforms not only on features, but also on alignment with business goals, cloud strategy, cost structure, and long-term scalability.
Overview of Leading Platforms and Their Core Strengths
Google BigQuery
This platform stands out for its serverless architecture and deep AI and machine learning integration. It is highly effective for querying massive datasets at speed and supports advanced analytics use cases. Its usage-based pricing offers flexibility but requires disciplined cost controls for heavy workloads.
Snowflake
Snowflake is recognized for its decoupled storage and compute model and true cloud-agnostic design. It enables secure data sharing and multi-cloud governance. While extremely flexible, sustained high usage can lead to higher operational costs if not carefully monitored.
Amazon Redshift
Redshift delivers strong performance and cost efficiency, particularly for organizations operating deeply within the AWS ecosystem. Recent security-by-default improvements and increasing AI integrations make it a compelling choice for AWS-first enterprises.
Microsoft Azure Synapse Analytics
This unified analytics solution is well-suited for large enterprises with complex data environments. Its close integration with Azure services and evolution toward a lake-centric model under Microsoft Fabric make it attractive for Microsoft-aligned organizations.
Oracle Autonomous Data Warehouse
Oracle differentiates itself through AI-driven automation. Self-tuning, self-scaling, and self-patching significantly reduce operational effort. It is especially suitable for regulated industries and hybrid cloud environments, though it may be less cost-effective for smaller teams.
Databricks
Databricks leads in lakehouse architecture and machine learning-driven analytics. It excels in complex data engineering and AI workloads and consistently demonstrates strong performance benchmarks. Pricing complexity means it is best suited for organizations with mature data strategies.
IBM Db2 Warehouse
IBM Db2 Warehouse offers reliable performance and strong hybrid deployment support. Its focus on AI-assisted database management and containerized portability makes it suitable for enterprises balancing on-premises and cloud environments.
PostgreSQL
PostgreSQL continues to gain enterprise adoption as a powerful open-source option. It delivers strong performance for complex queries and benefits from a large innovation-driven community. While software costs are minimal, operational expertise is essential for long-term success.
Teradata Vantage
Teradata Vantage is designed for large-scale analytics with trusted AI and hybrid multi-cloud flexibility. Its strength lies in handling massive datasets and supporting data fabric architectures that democratize analytics across the enterprise.
SAP Datasphere
SAP Datasphere is evolving into a business data fabric that unifies integration, virtualization, and analytics. It is particularly valuable for SAP-centric organizations seeking self-service analytics and consistent business semantics across systems.
Azure SQL Database
This platform is well-suited for mid-sized data warehouses and operational analytics. It offers automated management, strong performance, and close alignment with Microsoft’s broader AI and Fabric roadmap.
Guidance for Selecting the Right Platform Based on Business Needs
Choosing the best data warehouse software in 2026 requires aligning platform capabilities with organizational priorities rather than following market popularity alone.
Organizations that are heavily focused on AI, machine learning, and advanced analytics will benefit most from Databricks and Google BigQuery. These platforms integrate AI deeply into both data management and analytics workflows.
Enterprises pursuing multi-cloud strategies to reduce vendor dependency should strongly consider Snowflake and Teradata Vantage. Their architectures are designed to operate consistently across multiple cloud providers and hybrid environments.
Companies deeply invested in a single cloud ecosystem can reduce complexity by choosing native solutions. Amazon Redshift aligns naturally with AWS environments, Azure Synapse Analytics and Azure SQL Database fit seamlessly into Microsoft ecosystems, and Google BigQuery complements Google Cloud-native stacks.
Cost-sensitive organizations with strong internal engineering capabilities may find PostgreSQL to be a compelling alternative. While it avoids licensing fees, it requires hands-on management and long-term operational commitment.
Enterprises seeking minimal administrative overhead and maximum automation should prioritize Oracle Autonomous Data Warehouse. Its AI-driven operations significantly reduce manual effort and operational risk.
Organizations managing complex hybrid IT landscapes should evaluate IBM Db2 Warehouse and Teradata Vantage. Both platforms emphasize portability, enterprise governance, and consistent analytics across environments.
SAP-centric enterprises aiming to unify analytics across business functions should consider SAP Datasphere. Its evolving data fabric approach supports governed self-service analytics while preserving business context.
Decision Alignment Matrix
Primary Business Priority | Platforms That Align Best
AI and machine learning leadership | Databricks, Google BigQuery
Multi-cloud flexibility | Snowflake, Teradata Vantage
Cloud ecosystem optimization | Redshift, Azure Synapse, BigQuery
Operational automation | Oracle Autonomous Data Warehouse
Cost efficiency with control | PostgreSQL, Azure SQL Database
Hybrid enterprise environments | IBM Db2 Warehouse, Teradata Vantage
SAP ecosystem integration | SAP Datasphere
Future Outlook for Data Warehousing
Looking ahead, data warehousing platforms are converging into broader data fabric architectures that unify analytics, governance, AI, and real-time intelligence.
Artificial intelligence will become pervasive across all layers of the data warehouse. AI will automate data preparation, optimization, governance, and security, effectively acting as an automated database administrator and reducing operational friction.
Architectural convergence will continue as lakehouse models become standard. Unified support for structured, semi-structured, and unstructured data will eliminate traditional data silos and simplify analytics pipelines.
Real-time analytics will shift from a competitive advantage to a baseline requirement. Near-instant data availability will be expected across industries, from finance and retail to manufacturing and healthcare.
Data trust will become a strategic focus. Governance will move beyond compliance to emphasize data quality, lineage transparency, and usability, ensuring that analytics outputs are reliable and actionable.
Hybrid and multi-cloud deployments will dominate enterprise strategies. Flexibility, interoperability, and data sovereignty will drive demand for platforms that can operate seamlessly across diverse infrastructure environments.
The Strategic Importance of Data Warehouse Selection
By 2026, the data warehouse is no longer a background technology. It is a core business asset that directly influences innovation, competitiveness, and digital transformation. Selecting the right platform requires a long-term perspective that balances performance, cost, governance, and strategic fit.
Organizations that approach data warehouse selection as a strategic decision rather than a technical procurement will be better positioned to extract maximum value from their data and adapt to future demands in an increasingly data-driven world.
Conclusion
As organizations move deeper into 2026, data warehousing has clearly evolved from a back-end infrastructure component into a central strategic pillar of digital transformation. The Top 10 Best Data Warehouse Software To Use in 2026 are no longer judged solely by their ability to store and query data. They are evaluated on how effectively they enable real-time insights, support artificial intelligence and machine learning, ensure data trust, and scale across increasingly complex cloud and hybrid environments.
One of the most important takeaways from this analysis is that there is no universally “best” data warehouse software for every organization. Each leading platform excels in specific areas, whether that is AI-driven automation, lakehouse architecture, multi-cloud flexibility, enterprise governance, or cost-efficient scalability. The right choice depends on how closely a platform aligns with an organization’s business model, data maturity, regulatory requirements, and long-term technology strategy.
A defining theme across all top platforms in 2026 is intelligent automation. AI is now embedded into core data warehouse operations, from performance tuning and scaling to governance, security, and even natural language interaction. This shift dramatically reduces operational overhead and allows data teams to focus on higher-value activities such as advanced analytics, predictive modeling, and business insight generation. Organizations that prioritize platforms with strong AI-assisted management capabilities will gain a clear operational and competitive advantage.
Another major trend shaping data warehouse selection is architectural convergence. The widespread adoption of lakehouse and data fabric concepts reflects the growing need to analyze structured, semi-structured, and unstructured data on a unified platform. Traditional boundaries between data lakes and data warehouses are disappearing, enabling more flexible analytics, streamlined pipelines, and stronger support for AI and machine learning workloads. Platforms that embrace this convergence are better positioned to handle the growing diversity and scale of enterprise data.
Real-time analytics has also become a baseline expectation rather than a differentiator. In 2026, businesses across industries rely on near-instant data to detect risks, personalize experiences, optimize operations, and respond to market changes. Data warehouse software that cannot support streaming ingestion and low-latency analytics risks becoming a bottleneck rather than a business enabler. Speed, concurrency, and responsiveness are now essential selection criteria.
Security, governance, and compliance remain non-negotiable, but the conversation has matured. Most leading platforms now meet global regulatory standards, making basic compliance a given. The real differentiator lies in advanced governance capabilities such as automated policy enforcement, data lineage tracking, metadata management, and data quality monitoring. In an era of AI-driven decision-making, data trust is as critical as data access. Organizations must choose platforms that ensure data is not only secure, but also accurate, discoverable, and usable at scale.
Cost efficiency is another critical factor that requires careful consideration. While cloud-based, pay-as-you-go pricing offers flexibility, it can also introduce unpredictability if workloads are not well understood or governed. Open-source and self-managed options may reduce licensing costs but increase operational responsibility. The most successful organizations in 2026 will be those that evaluate total cost of ownership holistically, balancing infrastructure, usage, staffing, and long-term scalability rather than focusing on headline pricing alone.
Multi-cloud and hybrid deployment support has emerged as a strategic necessity. Enterprises increasingly demand flexibility to avoid vendor lock-in, meet data sovereignty requirements, and optimize workloads across different environments. Data warehouse platforms that offer seamless portability and consistent performance across clouds provide greater resilience and future-proofing.
Ultimately, selecting the best data warehouse software in 2026 is not a purely technical decision. It is a strategic business choice that directly impacts an organization’s ability to innovate, compete, and grow in a data-driven economy. The platforms highlighted in this guide represent the strongest options available today, each offering unique strengths tailored to different use cases and organizational priorities.
Organizations that take the time to align platform capabilities with their data strategy, invest in governance and automation, and plan for future scalability will be best positioned to unlock the full value of their data. In 2026 and beyond, the most successful enterprises will not be those with the most data, but those with the most intelligent, trusted, and adaptable data platforms at their core.
If you find this article useful, why not share it with your hiring manager and C-level suite friends and also leave a nice comment below?
We, at the 9cv9 Research Team, strive to bring the latest and most meaningful data, guides, and statistics to your doorstep.
To get access to top-quality guides, click over to 9cv9 Blog.
To hire top talents using our modern AI-powered recruitment agency, find out more at 9cv9 Modern AI-Powered Recruitment Agency.
People Also Ask
What is data warehouse software used for in 2026
Data warehouse software is used to store, process, and analyze large volumes of data from multiple sources, enabling reporting, analytics, AI models, and real-time business insights at scale.
Which is the best data warehouse software in 2026
The best data warehouse software in 2026 depends on business needs, but leading options include cloud-native, AI-enabled, and lakehouse-based platforms offering scalability, security, and automation.
Is cloud data warehouse better than on-premise in 2026
Yes, cloud data warehouses dominate in 2026 due to lower infrastructure overhead, elastic scalability, faster deployment, built-in security, and support for AI and real-time analytics.
What is a lakehouse data warehouse
A lakehouse combines data warehouse performance with data lake flexibility, allowing structured and unstructured data to be analyzed together using a single, governed data platform.
Which data warehouse is best for AI and machine learning
Data warehouses with native AI integration, lakehouse architecture, and support for large-scale analytics are best suited for machine learning and advanced AI workloads in 2026.
Are data warehouses still relevant in 2026
Yes, data warehouses remain critical in 2026 as they power analytics, AI, compliance, and decision-making across enterprises, evolving into intelligent data platforms.
What features should a data warehouse have in 2026
Key features include AI-driven automation, real-time analytics, strong security, governance, scalability, support for diverse data types, and integration with analytics and BI tools.
How much does data warehouse software cost in 2026
Costs vary widely based on usage, storage, and compute. Pricing models include pay-as-you-go, reserved capacity, and open-source options with infrastructure and operational costs.
Is open-source data warehouse software reliable
Open-source solutions can be highly reliable and performant, but they require strong internal expertise for security, scaling, maintenance, and long-term operational management.
What is the difference between data warehouse and data lake
A data warehouse stores structured, cleaned data for analytics, while a data lake stores raw data in various formats. Lakehouse platforms combine both approaches.
Which data warehouse is best for real-time analytics
Platforms with streaming ingestion and low-latency query execution are best for real-time analytics, enabling instant insights and faster business decisions.
Can small businesses use enterprise data warehouses
Yes, many modern data warehouses scale down efficiently, allowing small and mid-sized businesses to use enterprise-grade analytics without heavy infrastructure investment.
What is serverless data warehouse software
Serverless data warehouses automatically manage infrastructure, scaling, and performance, allowing users to focus on analytics without managing servers or capacity.
Is data warehouse security important in 2026
Security is critical in 2026, with data warehouses handling sensitive information and requiring encryption, access controls, governance, and compliance with global regulations.
What compliance standards should data warehouses support
Modern data warehouses commonly support standards like GDPR, HIPAA, SOC 2, and ISO 27001 to meet enterprise and regulatory requirements.
How do data warehouses support business intelligence tools
Data warehouses integrate with BI tools to power dashboards, reports, and visual analytics, enabling users to explore and analyze data efficiently.
What is data warehouse automation
Automation uses AI to handle tuning, scaling, patching, and governance, reducing manual administration and improving performance and reliability.
Which data warehouse is best for multi-cloud environments
Multi-cloud-friendly data warehouses allow consistent deployment across different cloud providers, helping organizations avoid vendor lock-in and improve resilience.
Can data warehouses handle unstructured data
Modern data warehouses and lakehouse platforms support unstructured and semi-structured data such as logs, text, and JSON alongside traditional structured data.
What is data fabric in data warehousing
A data fabric is an architecture that connects data across systems, enabling unified access, governance, and analytics without heavy data movement.
How do data warehouses support data governance
They offer tools for access control, data lineage, cataloging, classification, and policy enforcement to ensure data trust and regulatory compliance.
What is the role of AI in data warehousing
AI automates data management, improves query performance, enhances security, enables natural language queries, and supports predictive analytics.
Are data warehouses expensive to run
Costs depend on usage patterns and platform choice. Poorly optimized workloads can increase costs, while automation and governance help control spending.
What industries benefit most from data warehouses
Industries such as finance, healthcare, retail, manufacturing, and technology benefit heavily due to analytics, compliance, and AI-driven insights.
How do data warehouses scale in 2026
They scale horizontally and vertically using cloud infrastructure, automatically adjusting compute and storage based on workload demands.
What is the future of data warehouse software
The future points toward AI-first, real-time, lakehouse-based platforms that integrate analytics, governance, and automation into a single data ecosystem.
Is data warehouse migration difficult
Migration complexity depends on data volume and architecture, but modern tools and cloud platforms simplify migration from legacy systems.
What is the difference between data warehouse and database
A database supports transactional workloads, while a data warehouse is optimized for analytics, reporting, and large-scale data processing.
Do data warehouses support SQL in 2026
Yes, SQL remains the primary query language, often enhanced with AI-assisted querying and support for semi-structured data formats.
How to choose the best data warehouse software
Organizations should evaluate performance, cost, AI capabilities, security, scalability, cloud strategy, and alignment with long-term business goals.
Sources
Market Research Future
Precedence Research
Research Nester
Improvado
ScienceSoft
Funnel
Google Cloud
MoldStud
Hexaware
Gartner
Moor Insights & Strategy
Firebolt
G2
Snowflake
DNAMIC
CelerData
Charter Global
PeerSpot
Chaos Genius
Snowflake Masters
Amazon Web Services
NovelVista
The Business Research Company
Microsoft Fabric Blog
CloudOptimo
CData Arc
Dev4Side
Estuary
Microsoft Azure
Microsoft Learn
Hevo Data
GlobeNewswire
Integrate
Oracle
Navisite
Upsolver
Sacra
Recordly
DataCamp
Databricks
Transaction Processing Performance Council
Expert Insights
Digitalogy
IBM
IBM Newsroom
Portable
Nucamp
Definite
Tekpon
Supabase
Yugabyte
Redgate Software
EnterpriseDB
Info-Tech
Teradata
SourceForge
Slashdot
BARC Research
TrustRadius
SAP
Collibra
Valantic
Skyvia
Microsoft
Microsoft Tech Community
Ataccama
Forrester




{kind=link}