





")













")






 To Try In 2024")
Key Takeaways
- Cutting-Edge Innovation: Explore the forefront of AI technology with our top 10 LLMs, showcasing the latest advancements and breakthroughs in natural language processing.
- Versatile Applications: From conversational assistants to data analysis, these LLMs offer a wide range of applications suitable for various industries and purposes.
- Enhanced User Experience: Discover LLMs that prioritize efficiency, performance, and user-centric design, revolutionizing the way we interact with artificial intelligence in 2024.
In the ever-evolving landscape of artificial intelligence, Large Language Models (LLMs) stand at the forefront, revolutionizing the way we interact with technology and shaping the future of human-machine communication.
As we step into 2024, the realm of LLMs has witnessed unprecedented growth and innovation, with each passing year bringing forth newer, more advanced models that push the boundaries of what’s possible.
If you’re intrigued by the power of language and the capabilities of AI, then you’re in for a treat.
In this comprehensive guide, we embark on a journey through the top 10 LLMs that are set to redefine the way we perceive and harness the potential of natural language processing in 2024.
But before we dive into the intricacies of these cutting-edge models, let’s take a moment to understand what LLMs are and why they matter in today’s digital landscape.
At their core, Large Language Models are sophisticated AI systems designed to understand and generate human-like text based on vast amounts of training data.
These models leverage deep learning techniques, particularly neural networks, to process and analyze linguistic patterns, enabling them to comprehend and generate text with remarkable fluency and coherence.
The significance of LLMs transcends mere convenience or novelty; they hold the key to a myriad of applications across diverse industries.
From facilitating more intuitive human-computer interactions to revolutionizing content generation, translation, sentiment analysis, and beyond, the potential applications of LLMs are virtually limitless.
As we venture further into the digital age, the demand for LLMs that are not only powerful but also versatile and user-friendly continues to soar.
Whether you’re a developer seeking to enhance your applications with natural language understanding or a content creator looking to streamline your workflow, finding the right LLM can make all the difference in unlocking new possibilities and driving innovation.
In this blog, we’ve meticulously curated a list of the top 10 LLMs that exemplify excellence in terms of performance, versatility, and usability.
These models have been rigorously evaluated based on a range of criteria, including language comprehension, generation capabilities, computational efficiency, and scalability, among others.
But our exploration doesn’t stop there.
We’ll delve deep into each LLM, providing insights into their unique features, strengths, and real-world applications.
Whether you’re a seasoned AI enthusiast or someone just beginning to explore the fascinating world of natural language processing, this guide aims to provide you with valuable insights and resources to navigate the complex landscape of LLMs with confidence and clarity.
So, join us as we embark on a journey through the realm of Large Language Models, and discover the transformative potential that awaits in 2024 and beyond.
Get ready to unlock the future of human-machine interaction and embark on a voyage of discovery with the top 10 LLMs of 2024.
Before we venture further into this article, we like to share who we are and what we do.
About 9cv9
9cv9 is a business tech startup based in Singapore and Asia, with a strong presence all over the world.
With over eight years of startup and business experience, and being highly involved in connecting with thousands of companies and startups, the 9cv9 team has listed some important learning points in this overview of the Top 10 Best Large Language Models (LLMs) To Try In 2024.
If your company needs recruitment and headhunting services to hire top-quality employees, you can use 9cv9 headhunting and recruitment services to hire top talents and candidates. Find out more here, or send over an email to [email protected].
Or just post 1 free job posting here at 9cv9 Hiring Portal in under 10 minutes.
Top 10 Best Large Language Models (LLMs) To Try In 2024
- GPT-4o
- Claude 3
- Grok-1.5V
- Mistral 7B
- Gemini Ultra
- Falcon 180B
- Llama 3
- Stable LM 2
- Gemma
- Inflection-2.5
1. GPT-4o

Released on May 13, 2024, GPT-4o emerges as the pinnacle of linguistic innovation, heralding a new era in natural language processing.
Developed by OpenAI, this groundbreaking model represents a quantum leap forward, surpassing its predecessors, including GPT-4, GPT-3.5, and GPT-3, in both capability and efficiency.
With its multifaceted approach to language comprehension and generation, GPT-4o stands poised to redefine the boundaries of human-computer interaction in 2024 and beyond.
What Sets GPT-4o Apart:
GPT-4o, or “omni” as signified by its moniker, embodies a holistic approach to language processing, integrating text, image, video, and voice capabilities within a single, unified framework.
Unlike its predecessors, which excelled primarily in textual analysis, GPT-4o expands its repertoire to encompass a diverse range of modalities, enabling seamless interaction across multiple mediums.
One of GPT-4o’s most notable enhancements lies in its Voice-to-Voice functionality, a feature that promises to revolutionize input response times.
With an unprecedented average latency of 320 milliseconds, GPT-4o outpaces its predecessors by a significant margin, approaching human-level responsiveness in conversational contexts.
This improvement represents a paradigm shift in human-computer interaction, facilitating more fluid and natural exchanges between users and AI systems.
Moreover, GPT-4o delivers unparalleled performance across a spectrum of tasks, from text analysis to code comprehension, particularly excelling in non-English languages.
With its enhanced vision and audio processing capabilities, GPT-4o sets a new standard for AI models, offering unprecedented accuracy and versatility in understanding multimedia inputs.
A Breakthrough in End-to-End Learning:
Prior to the advent of GPT-4o, voice interactions with AI systems were constrained by cumbersome pipelines and latency issues.
However, with GPT-4o’s pioneering end-to-end learning approach, these limitations become a relic of the past.
By training a single, cohesive model encompassing text, vision, and audio modalities, OpenAI has transcended traditional boundaries, enabling seamless integration of diverse inputs and outputs.
GPT-4o’s end-to-end learning architecture not only streamlines the interaction process but also enhances the model’s ability to capture nuanced nuances such as tone, multiple speakers, and background noises.
This breakthrough empowers GPT-4o to deliver more immersive and engaging user experiences, surpassing the capabilities of its predecessors by orders of magnitude.
Looking Towards the Future:
As we embark on this journey with GPT-4o, we are only beginning to scratch the surface of its vast potential.
With each passing day, researchers and developers continue to explore new avenues and applications for this groundbreaking model, uncovering its capabilities and limitations in equal measure.
In summary, GPT-4o represents a watershed moment in the evolution of AI-driven language processing.
Its unparalleled versatility, efficiency, and responsiveness position it as a frontrunner in the realm of large language models, promising to shape the future of human-computer interaction in profound and unforeseen ways.
As we venture forth into uncharted territory, the possibilities with GPT-4o are limited only by our imagination.
2. Claude 3

Launched on March 14, 2024, Claude 3 emerges as the latest triumph from Anthropic, introducing a new paradigm in language modeling technology.
Comprising three distinct iterations – Claude 3 Haiku, Claude 3 Sonnet, and Claude 3 Opus – this formidable model family redefines industry standards, offering unparalleled performance and versatility across a spectrum of cognitive tasks.
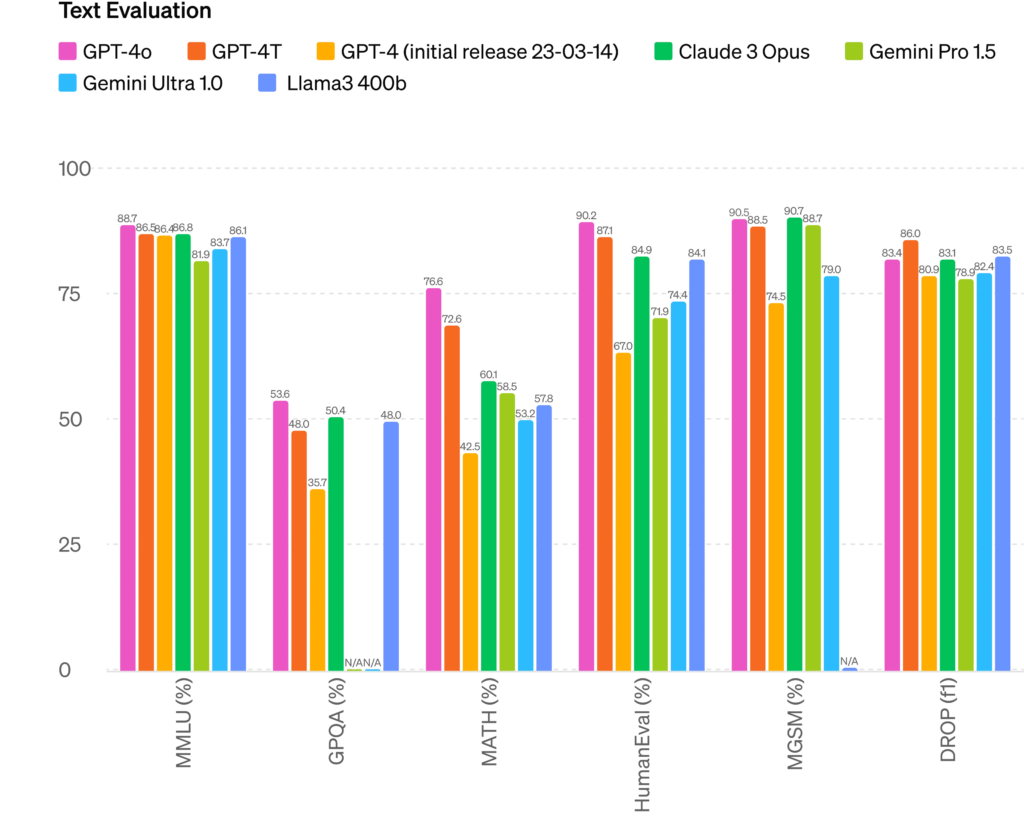
With each iteration representing a leap forward in capability, Claude 3 asserts itself as a formidable contender in the realm of large language models, challenging established titans like GPT-4 and ChatGPT.
Unprecedented Capabilities:
Claude 3 stands out as a game-changer in the world of natural language processing, boasting the ability to process an astounding 200,000 tokens (equivalent to 150,000 words).
This remarkable feat eclipses the capabilities of its competitors, including GPT-4, which pales in comparison with its 32,000 token limit.
Backed by Amazon’s substantial investment of over $4 billion, Anthropic has catapulted to a valuation of $15 billion, signaling widespread recognition of Claude’s disruptive potential.
Below is a comparison of the Claude 3 models to other LLMs on multiple benchmarks of capability:
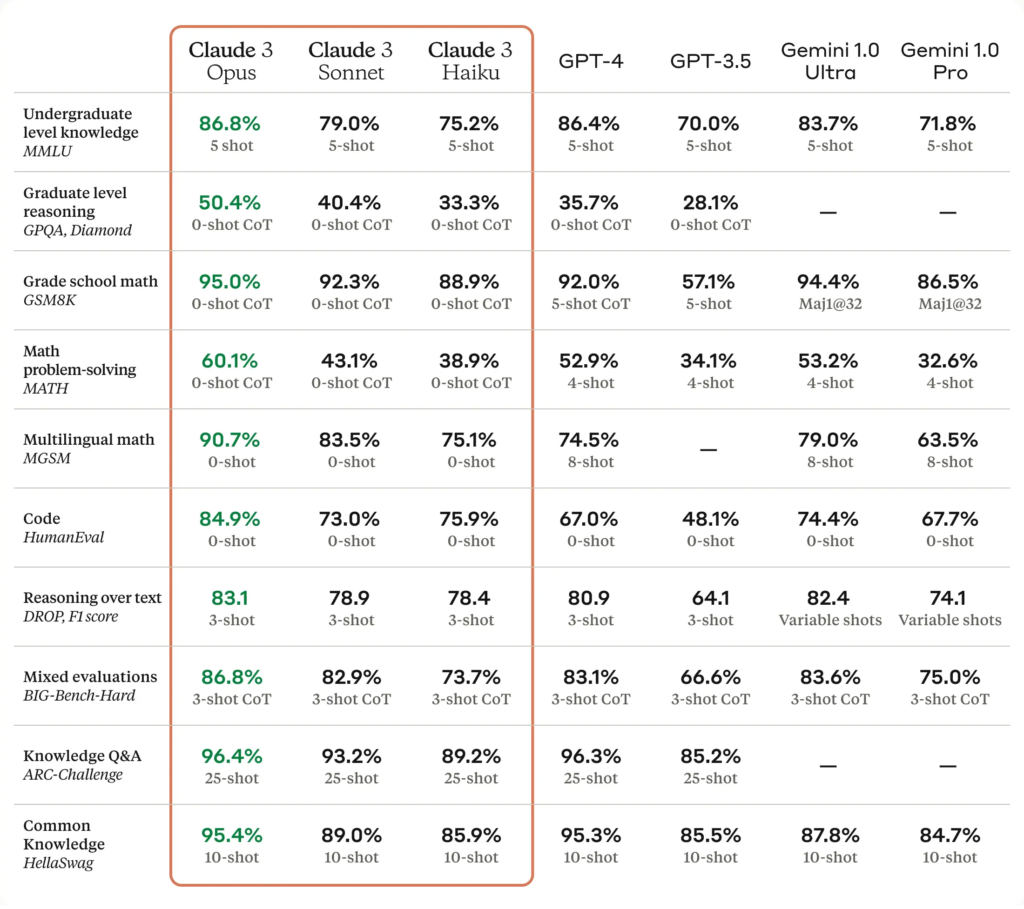
State-of-the-Art Performance:
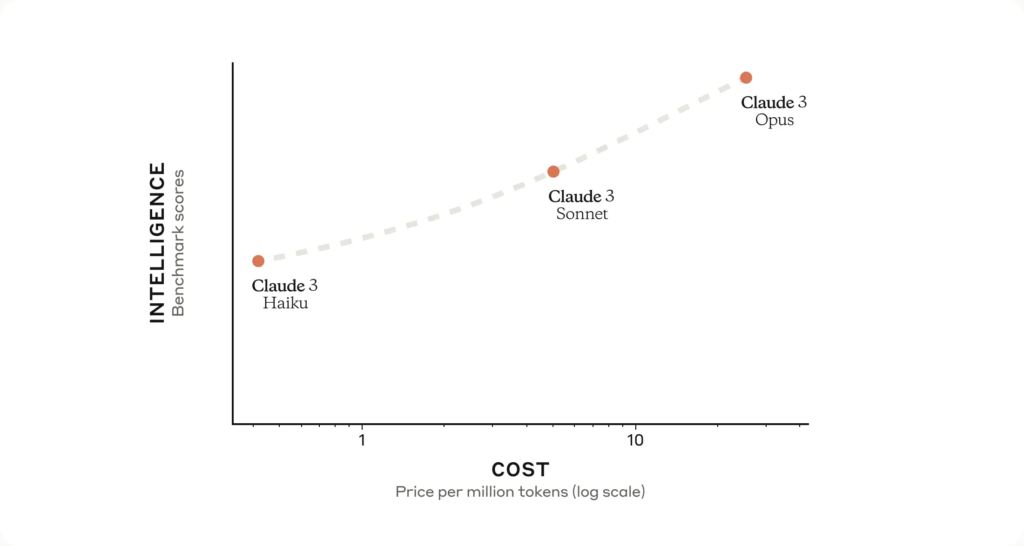
The Claude 3 model family introduces a hierarchy of intelligence, with each subsequent iteration raising the bar for excellence in language processing.
From the swift and cost-effective Haiku to the formidable Opus, users can choose the ideal balance of intelligence, speed, and cost to suit their specific needs.
Opus, the pinnacle of the Claude 3 lineup, surpasses its peers in a multitude of evaluation benchmarks, demonstrating near-human levels of comprehension and fluency across complex tasks.
Real-Time Responsiveness:
One of Claude 3’s most compelling features is its ability to deliver near-instantaneous results, making it ideal for applications requiring live customer interactions, auto-completions, and real-time data extraction tasks.
Haiku, renowned for its lightning-fast processing speed, can dissect information-dense research papers on platforms like arXiv in under three seconds, setting a new standard for efficiency and agility in language processing.
Enhanced Vision Capabilities:
In addition to its prowess in text analysis, the Claude 3 models boast sophisticated vision capabilities, enabling them to process a wide array of visual formats, including photos, charts, graphs, and technical diagrams.
This groundbreaking feature holds particular significance for enterprise customers, many of whom rely heavily on visual knowledge bases encoded in various formats such as PDFs and presentation slides.
Summary:
As Anthropic unveils the Claude 3 model family, the landscape of language modeling undergoes a seismic shift, with Claude asserting its dominance as a frontrunner in the field.
With unparalleled capabilities, real-time responsiveness, and enhanced vision processing, Claude 3 sets a new standard for excellence in natural language understanding and generation.
As industries embrace the transformative potential of Claude 3, the possibilities for innovation and advancement are limitless, paving the way for a future where human-machine interaction reaches unprecedented levels of sophistication and efficiency.
3. Grok-1.5V

Launched on April 12, 2024, Grok-1.5V by xAI marks a significant advancement in the realm of multimodal AI models.
This first-generation model not only excels in text processing but also boasts the ability to comprehend a wide array of visual information, setting a new benchmark in the industry.
Grok-1.5V is poised to redefine AI capabilities, making it one of the most sophisticated and versatile language models available in 2024.
Grok-1.5V represents a monumental leap in AI technology with its robust multimodal functionality.
This model is capable of processing and understanding complex visual inputs such as documents, diagrams, charts, screenshots, and photographs.
Its enhanced visual comprehension enables Grok-1.5V to interpret and analyze diverse types of information seamlessly, making it an invaluable tool across various domains.
Unparalleled Performance Across Domains:
In terms of performance, Grok-1.5V stands shoulder to shoulder with the most advanced multimodal models available today.
Its capabilities extend from multidisciplinary reasoning to detailed document analysis and the interpretation of scientific diagrams and charts.
One of the standout features of Grok-1.5V is its exceptional performance in understanding and processing real-world spatial information, as evidenced by its superior results in the new RealWorldQA benchmark.

Advanced Reasoning and Computational Prowess:
xAI has significantly enhanced Grok-1.5V’s reasoning abilities, particularly in coding and mathematical tasks. The model’s prowess in these areas is highlighted by its more than doubled score on the MATH benchmark compared to its predecessor, Grok-1.
Additionally, Grok-1.5V achieved over a 10 percentage point increase on the HumanEval test, which assesses programming language generation and problem-solving skills.
These improvements underscore Grok-1.5V’s advanced computational abilities, making it a formidable tool for technical and scientific applications.
High Context Processing Capacity:
Another remarkable feature of Grok-1.5V is its capacity to process contexts up to 128,000 tokens.
This extensive context window allows the model to handle large and complex datasets with ease, facilitating more comprehensive and nuanced analysis.
This capability is particularly beneficial for applications requiring in-depth examination of lengthy documents or intricate datasets.
Summary:
As we witness the launch of Grok-1.5V, it is evident that xAI has set a new standard in the AI industry with its pioneering multimodal capabilities.
Grok-1.5V’s exceptional performance in text and visual processing, coupled with its advanced reasoning and high context capacity, positions it as one of the leading AI models of 2024.
This model not only enhances our understanding of the physical world but also paves the way for future innovations in AI technology.
As Grok-1.5V becomes available to early testers and existing users, its impact on various industries is poised to be profound, heralding a new era of sophisticated and versatile AI applications.
4. Mistral 7B

In the rapidly evolving landscape of artificial intelligence, Mistral 7B emerges as a groundbreaking open-source language model, setting new benchmarks for performance and efficiency.
Developed with a sophisticated architecture of 32 layers, 32 attention heads, and eight key-value heads, Mistral 7B stands out as one of the most advanced and versatile models of 2024.
This model’s remarkable capabilities make it a formidable contender in the AI domain, particularly against other leading models such as Llama 2.
Mistral 7B’s architecture is a marvel of modern AI engineering.
With its 7.3 billion parameters, the model leverages Grouped-query attention (GQA) and Sliding Window Attention (SWA) to optimize performance.
GQA enables faster inference, significantly reducing the time required to generate responses.
SWA allows the model to handle longer sequences efficiently, ensuring high performance at a reduced computational cost.
These innovations make Mistral 7B not only powerful but also highly efficient, enabling it to manage complex tasks with greater speed and accuracy.
Unmatched Performance:
Mistral 7B sets itself apart by outperforming the Llama 2 family across a wide range of benchmarks. Whether it’s MMLU, reading comprehension, mathematics, coding, or other metrics, Mistral 7B consistently delivers superior results.
Notably, it surpasses the Llama 2 13B model on all benchmarks and even outperforms the Llama 1 34B model on several fronts.
Furthermore, Mistral 7B approaches the performance of CodeLlama 7B in coding tasks while maintaining strong capabilities in English language processing.
This comprehensive excellence underscores Mistral 7B’s versatility and robustness in handling diverse tasks.
Open-Source Accessibility:
Released under the Apache 2.0 license, Mistral 7B is freely available for download and deployment.
This open-source model can be easily integrated into local environments, deployed on cloud platforms, or run on HuggingFace, providing users with unparalleled flexibility and control.
This accessibility ensures that a wide range of users, from individual developers to large enterprises, can leverage Mistral 7B’s advanced capabilities to enhance their applications and research projects.
Innovative Applications:
Mistral 7B’s advanced architecture and superior performance open up a multitude of applications across various fields.
Its ability to process longer sequences at a lower cost makes it ideal for tasks requiring extensive context analysis, such as legal document review, academic research, and comprehensive data analysis.
Additionally, its prowess in coding and mathematics positions it as a valuable tool for software development, algorithm optimization, and educational purposes.
Summary:
Mistral 7B represents a significant leap forward in the world of language models, combining architectural innovation with unmatched performance.
Its superior capabilities across a range of benchmarks, coupled with its open-source accessibility, make it one of the most compelling AI models of 2024.
As users explore the vast potential of Mistral 7B, it is poised to drive innovation and excellence across multiple domains, solidifying its place as a leader in the AI landscape.
5. Gemini Ultra

In the ever-evolving field of artificial intelligence, Gemini 1.0 Ultra emerges as a paragon of advanced AI capabilities, optimized for delivering high-quality performance across a myriad of complex tasks.
Developed with an emphasis on excellence in coding, reasoning, and multilingual support, Gemini 1.0 Ultra stands as one of the most sophisticated language models available in 2024.
This model’s exceptional features and robust performance set it apart, making it a premier choice for a wide range of applications.
Multimodal Reasoning:
Gemini 1.0 Ultra is designed to natively understand and reason across various sequences, including audio, images, and text. This multimodal reasoning capability enables the model to interpret and analyze diverse types of information, making it incredibly versatile and effective in handling complex, real-world tasks.
Superior Coding Capabilities:
Gemini 1.0 Ultra excels in complex coding tasks, achieving state-of-the-art performance, particularly when integrated with AlphaCode 2. Its advanced coding proficiency allows it to tackle intricate programming challenges, offering solutions that are on par with, or even surpass, those provided by human coders.
Advanced Mathematical Reasoning:
The model’s analytical prowess is further highlighted by its strong performance on competition-grade mathematical problem sets.
Gemini 1.0 Ultra’s advanced mathematical reasoning abilities make it an invaluable tool for academic research, educational purposes, and any field requiring high-level quantitative analysis.
Unparalleled Multitask Performance:
Gemini 1.0 Ultra is the first model to outperform human experts on the Massive Multitask Language Understanding (MMLU) benchmark.
This benchmark encompasses 57 subjects, including math, physics, history, law, medicine, and ethics, testing both world knowledge and problem-solving abilities.
Gemini 1.0 Ultra’s superior performance across such a broad spectrum of disciplines underscores its comprehensive knowledge and exceptional problem-solving skills.

Why Gemini 1.0 Ultra Stands Out:
Gemini 1.0 Ultra is optimized for high-quality output, making it a standout model for intricate tasks requiring nuanced understanding and sophisticated reasoning.
Its ability to seamlessly process and integrate information from multiple modalities (audio, images, and text) provides a holistic approach to problem-solving.
This multimodal capacity, combined with its unparalleled coding and mathematical abilities, positions Gemini 1.0 Ultra at the forefront of AI innovation.
Furthermore, Gemini 1.0 Ultra’s achievement in the MMLU benchmark highlights its exceptional versatility and depth of knowledge across diverse subject areas.
This makes it a powerful tool not only for technical tasks but also for applications in education, research, law, medicine, and more.
Summary:
Gemini 1.0 Ultra represents a significant advancement in the field of AI, setting new standards for performance and versatility in 2024.
Its unique combination of multimodal reasoning, superior coding capabilities, advanced mathematical reasoning, and unmatched multitask performance solidifies its status as one of the best language models in the world.
As Gemini 1.0 Ultra continues to be integrated into various applications, its impact on the landscape of AI and its contribution to solving complex, real-world problems will be profound and far-reaching.
6. Falcon 180B

The Falcon 180B, developed and funded by the UAE-based Technology Innovation Institute (TII), represents a monumental leap in the evolution of large language models.
Released on September 6, 2023, Falcon 180B boasts an impressive 180 billion parameters, making it 4.5 times larger than its predecessor, Falcon 40B.
This model not only surpasses its earlier version but also outshines other prominent models such as GPT-3.5 and LLaMA 2 in various tasks, establishing itself as one of the best language models in the world in 2024.
Exceptional Capabilities:
Advanced Reasoning and Comprehension:
Falcon 180B excels in complex reasoning, question answering, and coding tasks, outperforming many of its contemporaries.
Its ability to handle sophisticated queries with ease positions it as a leading model in natural language understanding and problem-solving.
Superior Performance Metrics:
With 180 billion parameters, Falcon 180B has been trained on a staggering 3.5 trillion tokens. This extensive training allows it to achieve remarkable proficiency across a wide range of benchmarks.
Currently, it holds the top position on the Hugging Face Leaderboard for pre-trained open large language models, highlighting its superior performance in both research and commercial applications.
Competitive Edge:
Despite being an open-access model, Falcon 180B rivals the capabilities of some of the best closed-source models.
It ranks just behind OpenAI’s GPT-4 and performs on par with Google’s PaLM 2 Large, which powers Bard, even though it is only half the size.
This demonstrates Falcon 180B’s efficiency and prowess in delivering high-quality outputs.
Why Falcon 180B Stands Out:
Optimal Inference Architecture:
Falcon 180B features an architecture optimized for inference, incorporating multi-query mechanisms (Shazeer et al., 2019). This optimization ensures faster and more accurate responses, making it ideal for a variety of applications requiring real-time processing.
Versatility and Accessibility:
Available under a permissive license, Falcon 180B is accessible for both research and commercial use. This flexibility allows a wide range of users to leverage its advanced capabilities without restrictive licensing constraints. Additionally, it is available in a raw, pre-trained format, which can be fine-tuned to suit specific use cases.
Leading the Open-Access Frontier:
As the best open-access model currently available, Falcon 180B outperforms notable models like LLaMA-2, StableLM, RedPajama, and MPT. Its dominance on the OpenLLM Leaderboard underscores its leading position in the AI community.
Specialized Variants:
For users seeking a model tailored for conversational tasks, Falcon-180B-Chat offers an optimized version that excels in handling generic instructions within chat formats. This variant provides enhanced utility for applications in customer service, virtual assistance, and interactive AI solutions.
Summary:
Falcon 180B stands as a testament to the rapid advancements in AI technology, offering an unparalleled combination of scale, performance, and accessibility.
Its exceptional capabilities across various tasks, coupled with its optimized architecture and permissive licensing, make it a standout choice for researchers and commercial entities alike.
As Falcon 180B continues to lead the charge in open-access AI models, it sets a new standard for what is achievable in the realm of large language models, paving the way for future innovations and applications.
7. Llama 3

In 2024, Meta AI unveiled Llama 3, the latest and most advanced iteration in its series of autoregressive large language models.
Available in both 8 billion and 70 billion parameter versions, Llama 3 sets new standards in the realm of AI, outperforming prominent models like Mistral 7B and Google’s Gemma 7B across various benchmarks, including Massive Multitask Language Understanding (MMLU), reasoning, coding, and mathematics.
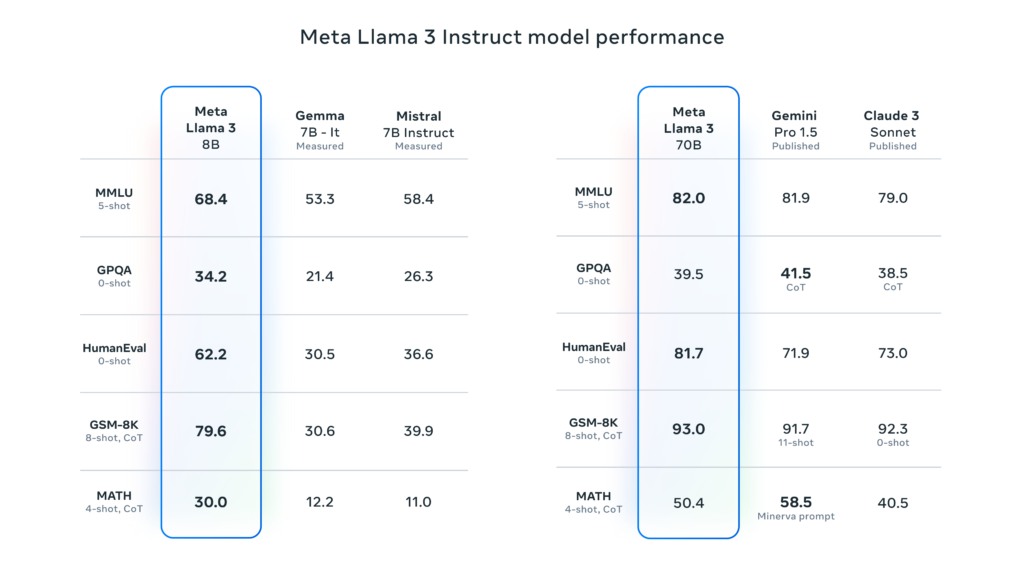
As an open-source model, Llama 3 can be accessed for free via the Meta AI chatbot, making its cutting-edge capabilities widely available.
Key Features and Innovations:
Superior Performance:
Llama 3 demonstrates remarkable proficiency across a wide range of industry benchmarks.
Both the 8B and 70B parameter models exhibit state-of-the-art performance, significantly surpassing their predecessors and other contemporary models.
This leap in performance is attributed to extensive pretraining and advanced post-training procedures, which have enhanced the models’ reasoning capabilities and overall accuracy.
Enhanced Pretraining and Fine-Tuning:
The models have been meticulously pretrained and instruction-fine-tuned, resulting in a substantial reduction in false refusal rates and improved alignment with user expectations.
This refinement process has also increased the diversity of model responses, ensuring more nuanced and contextually appropriate outputs.
These improvements position Llama 3 as the leading model at the 8B and 70B parameter scales.
Advanced Tokenization and Efficiency:
Llama 3 employs a tokenizer with an expansive vocabulary of 128K tokens, enabling more efficient language encoding and significantly boosting model performance.
This advanced tokenization method enhances the model’s ability to understand and generate complex language structures, contributing to its superior output quality.
Optimized Inference with Grouped Query Attention:
To enhance inference efficiency, Llama 3 integrates grouped query attention (GQA) across both its 8B and 70B versions.
This optimization ensures faster and more accurate responses, making the models highly effective for real-time applications.
Additionally, the models have been trained on sequences of 8,192 tokens, using masking techniques to maintain focus within document boundaries, thereby improving context retention and coherence.
Why Llama 3 Stands Out:
Cutting-Edge Multimodal Capabilities:
Llama 3 is designed to handle a wide array of tasks, from complex reasoning and coding to advanced mathematical problem-solving.
Its ability to outperform other leading models on critical benchmarks underscores its versatility and robustness in handling diverse applications.
Open-Source Accessibility:
As an open-source model, Llama 3 provides unparalleled access to cutting-edge AI technology.
Researchers, developers, and businesses can freely utilize the model via the Meta AI chatbot, fostering innovation and enabling a broader range of applications across various industries.
Future Prospects:
Meta AI has announced plans to release an even more powerful 400 billion-parameter version of Llama 3 later this year.
This upcoming iteration is expected to further push the boundaries of what large language models can achieve, promising even greater performance and capabilities.
Comprehensive Model Lineup:
In addition to the new Llama 3 models, Meta AI continues to support Llama 2, available in 7 billion, 13 billion, and 70 billion parameter versions.
This comprehensive lineup ensures that users can select the model that best fits their specific needs, whether they require the advanced features of Llama 3 or the established performance of Llama 2.
Summary:
Llama 3 represents a significant advancement in AI technology, setting new benchmarks for performance, efficiency, and accessibility.
With its superior capabilities in reasoning, coding, and mathematical problem-solving, Llama 3 stands as one of the best large language models in the world in 2024.
As Meta AI continues to innovate and expand the Llama series, the future of AI looks brighter than ever, promising transformative impacts across a multitude of sectors.
8. Stable LM 2

In the rapidly evolving landscape of artificial intelligence, Stability AI has once again set a new benchmark with the release of Stable LM 2.
Known for their groundbreaking work on the Stable Diffusion text-to-image model, Stability AI continues to innovate with this latest series of large language models.
Comprising Stable LM 2 12B and Stable LM 2 1.6B, these models offer exceptional performance, versatility, and accessibility, making them some of the best AI models available in 2024.
Key Features and Innovations:
Superior Performance in a Compact Form:
The Stable LM 2 12B, with its 12 billion parameters, significantly outperforms much larger models like LLaMA 2 70B on essential benchmarks, demonstrating Stability AI’s expertise in optimizing model architecture and training processes.
This remarkable efficiency allows it to deliver high-quality outputs without the extensive computational requirements typically associated with larger models.

Multilingual Mastery:
The Stable LM 2 1.6B model, boasting 1.6 billion parameters, is designed for multilingual proficiency.
It has been meticulously trained on data in seven languages: English, Spanish, German, Italian, French, Portuguese, and Dutch.
This capability ensures robust performance across diverse linguistic contexts, making it an invaluable tool for global applications.
Accessibility and Lowered Hardware Barriers:
One of the standout features of Stable LM 2 is its accessibility.
The compact size and efficiency of the 1.6B model reduce the hardware requirements, enabling more developers to engage with advanced generative AI technologies.
This democratization of AI tools fosters innovation and allows a broader spectrum of users to participate in the generative AI ecosystem.
Comprehensive Training and Fine-Tuning Support:
Stable LM 2 is available in both pre-trained and instruction-tuned versions.
Additionally, Stability AI provides the last checkpoint before the pre-training cooldown, along with optimizer states.
This comprehensive support facilitates fine-tuning and experimentation, empowering developers to tailor the models to their specific needs and use cases.
Commercial and Non-Commercial Use:
Stable LM 2 models are available for both commercial and non-commercial use. By obtaining a Stability AI Membership, users can access these powerful models and integrate them into a wide range of applications.
The models are also available for testing on Hugging Face, providing an easy entry point for experimentation and development.
Why Stable LM 2 Stands Out:
Exceptional Efficiency:
Despite its relatively smaller size, the 12B model outperforms much larger competitors, highlighting Stability AI’s skill in creating efficient and powerful AI models.
This efficiency translates to lower operational costs and faster processing times, making it ideal for real-time applications.
Multilingual Versatility:
The 1.6B model’s multilingual capabilities make it a versatile tool for international applications, ensuring high performance across different languages and cultural contexts.
This versatility is particularly valuable for businesses and developers operating in global markets.
Democratizing AI:
By lowering the hardware barriers, Stability AI enables more developers to participate in the AI revolution. This inclusivity is crucial for driving innovation and expanding the reach of advanced AI technologies.
Robust Support for Development:
The inclusion of pre-training checkpoints and optimizer states provides developers with the tools they need for effective fine-tuning and customization.
This support enhances the usability of Stable LM 2 and enables more precise and tailored applications.
Summary:
Stable LM 2 from Stability AI represents a significant advancement in the field of large language models, combining exceptional performance, multilingual proficiency, and broad accessibility.
With its superior efficiency and support for development, Stable LM 2 stands out as one of the best AI models of 2024.
Whether for commercial or non-commercial use, these models are set to drive innovation and expand the horizons of what is possible with artificial intelligence.
9. Gemma

In 2024, Google DeepMind introduced Gemma, a series of lightweight, open-source language models designed to set new standards in AI performance and accessibility.
Available in 2 billion and 7 billion parameter sizes, Gemma models leverage the advanced technology behind Google’s Gemini models while being tailored exclusively for text inputs and outputs.
These models are not only powerful and efficient but also embody Google’s commitment to responsible AI development.
Key Features and Innovations:
Cutting-Edge Performance:
Gemma models are built using the same sophisticated research and technology that underpin the acclaimed Gemini models.
Despite their smaller sizes, Gemma 2B and 7B deliver best-in-class performance, outperforming many larger models on key benchmarks.
This exceptional efficiency enables these models to run seamlessly on standard developer laptops or desktop computers, making advanced AI capabilities more accessible than ever.
Extensive Context Window:
With a context window of 8,000 tokens, Gemma models can handle complex and lengthy inputs with ease.
This feature enhances their ability to maintain coherence and relevance over extended dialogues or documents, making them ideal for a wide range of applications from academic research to customer service.
Robust and Safe AI:
Adhering to Google’s AI Principles, Gemma models are designed with safety and reliability at their core.
The development process includes automated techniques to filter out personal and sensitive information from training data, ensuring user privacy and data security.
Moreover, extensive fine-tuning and reinforcement learning from human feedback (RLHF) have been employed to align the models with ethical and responsible behaviors.
Comprehensive Evaluation and Testing:
To mitigate risks and enhance reliability, Gemma models undergo rigorous evaluations, including manual red-teaming, automated adversarial testing, and assessments of their capabilities in potentially harmful activities.
These proactive measures ensure that Gemma models not only perform exceptionally well but also adhere to high standards of safety and ethical use.
Tools for Developer Innovation:
Alongside the model weights, Google DeepMind provides a suite of tools designed to support developer innovation and collaboration.
These resources facilitate the integration and application of Gemma models across various domains, fostering a community of responsible AI practitioners dedicated to pushing the boundaries of what is possible.
Why Gemma Stands Out:
Unmatched Efficiency and Accessibility:
Gemma models, with their compact size and high performance, democratize access to advanced AI technologies.
They allow developers to harness cutting-edge AI capabilities without the need for extensive computational resources, thereby lowering barriers to entry and fostering broader participation in AI innovation.
Responsible AI Development:
Google DeepMind’s commitment to ethical AI development is evident in every aspect of Gemma’s design and deployment.
The models are engineered to minimize risks and enhance safety, making them reliable tools for diverse applications while maintaining the highest standards of user trust and data integrity.
Versatile Applications:
From handling complex textual analyses to supporting real-time interactions, Gemma models excel across a wide array of tasks.
Their ability to maintain context over long sequences makes them particularly valuable for applications requiring deep understanding and nuanced responses.
Future-Ready Technology:
By incorporating state-of-the-art techniques and rigorous safety protocols, Gemma models represent a forward-looking approach to AI.
They are designed not only to meet current needs but also to anticipate and adapt to future challenges, ensuring they remain relevant and effective in a rapidly evolving technological landscape.
Summary:
Gemma by Google DeepMind stands as a testament to the power of innovation and responsible AI development in 2024.
With its superior performance, extensive safety measures, and accessibility, Gemma sets a new benchmark for what lightweight language models can achieve.
As these models become integral to various industries and applications, they will undoubtedly drive the next wave of AI advancements, ensuring a future where technology serves humanity with unparalleled efficiency and ethical integrity.
10. Inflection-2.5

Inflection-2.5 represents a landmark achievement by Inflection AI in the realm of large language models (LLMs).
This latest iteration powers Pi, Inflection AI’s cutting-edge conversational assistant, and is celebrated for its remarkable efficiency and performance.
Despite utilizing only 40% of the training FLOPs of GPT-4, Inflection-2.5 delivers over 94% of GPT-4’s average performance, positioning it as one of the premier LLMs in the world for 2024.
Key Features and Innovations:
Exceptional Performance and Efficiency:
Inflection-2.5 is designed to rival the capabilities of leading models such as GPT-4 and Gemini.
It stands out by achieving high performance levels while maintaining remarkable computational efficiency.
This model has been fine-tuned to balance raw capability with empathetic, user-friendly interactions, making it an ideal choice for powering conversational AI.

Technological Advancements:
Inflection-2.5 showcases significant improvements in areas such as coding and mathematics, translating to superior performance on industry benchmarks.
Its efficiency in training is particularly noteworthy; despite using only 40% of GPT-4’s training compute, it manages to deliver nearly equivalent performance, marking a substantial leap in AI training methodologies.
Real-Time Information Integration:
One of the standout features of Inflection-2.5 is its integration of real-time web search capabilities.
This ensures that Pi, the conversational AI assistant it powers, can provide users with up-to-date information and high-quality, current news, enhancing the assistant’s relevance and utility in everyday use.
Superior Benchmark Performance:
Inflection-2.5 has demonstrated substantial gains over its predecessor, Inflection-1, particularly on the Massive Multitask Language Understanding (MMLU) benchmark.
This benchmark evaluates AI performance across a diverse array of tasks, ranging from high school to professional-level difficulty. The model’s impressive results underscore its advanced reasoning and problem-solving abilities.
Why Inflection-2.5 Stands Out:
Unmatched Efficiency:
The efficiency of Inflection-2.5 is a game-changer.
By achieving over 94% of GPT-4’s performance with only 40% of the training FLOPs, it sets a new standard for computationally efficient AI models.
This makes it an attractive option for organizations looking to leverage advanced AI capabilities without the hefty computational costs typically associated with such models.
Enhanced User Experience:
Inflection-2.5 powers Pi, which is accessible across multiple platforms including iOS, Android, and a new desktop app.
This wide availability ensures that users can benefit from its advanced capabilities regardless of their preferred device.
Moreover, the model’s empathetic fine-tuning ensures interactions are not only intelligent but also engaging and personable.
Robust Real-Time Capabilities:
The integration of real-time web search capabilities means that Pi can deliver the latest information quickly and accurately.
This feature is crucial for applications requiring timely data, such as customer support, news dissemination, and dynamic decision-making processes.
Leading the Technological Frontier:
Inflection-2.5’s advancements in coding, mathematics, and general IQ-oriented tasks highlight its role at the cutting edge of AI technology.
By continually pushing the boundaries of what AI can achieve, Inflection-2.5 ensures that users are always equipped with the most advanced tools available.
Summary:
Inflection-2.5 by Inflection AI is a testament to the strides being made in the field of artificial intelligence in 2024.
With its superior performance, remarkable efficiency, and user-centric design, it stands as one of the best large language models available today.
Whether for research, professional use, or personal assistance, Inflection-2.5 promises to deliver unparalleled AI capabilities, setting a new benchmark for the industry.
Conclusion
In conclusion, as we delve into the landscape of large language models (LLMs) in 2024, it’s evident that the realm of artificial intelligence is advancing at an unprecedented pace.
With the emergence of cutting-edge technologies and the continuous refinement of existing models, users now have access to a diverse array of LLMs that cater to various needs and preferences.
From the groundbreaking innovations of GPT-4o by OpenAI to the efficiency and performance of Gemma by Google DeepMind, each model offers unique features and capabilities that contribute to its prominence in the AI landscape.
Whether it’s the multilingual mastery of Stable LM 2 by Stability AI or the real-time information integration of Inflection-2.5 by Inflection AI, these LLMs represent the pinnacle of AI achievement in 2024.
As users explore these top 10 best LLMs, they are not only tapping into state-of-the-art technology but also shaping the future of AI-driven interactions and applications.
The versatility and sophistication of these models empower users across industries, from healthcare and finance to education and entertainment, to leverage AI in transformative ways.
Moreover, the continuous advancements in LLMs reflect a commitment to innovation and excellence within the AI community.
Developers are not only pushing the boundaries of what is possible but also prioritizing ethical considerations, safety, and user experience.
This dedication ensures that as AI evolves, it does so responsibly and with the best interests of humanity in mind.
In the coming years, we can expect further breakthroughs in AI technology, with LLMs playing a central role in driving these advancements.
As researchers and developers continue to collaborate and innovate, the possibilities for AI-driven solutions are limitless.
Whether it’s enhancing natural language understanding, revolutionizing customer service, or accelerating scientific discoveries, LLMs are poised to shape the future in profound ways.
So, as we embark on this journey through the top 10 best LLMs to try in 2024, let us embrace the transformative power of AI and harness its potential to create a better, more connected world.
With each interaction, each discovery, and each application, we are not just experiencing AI—we are shaping it, shaping our future, and shaping the world around us.
If your company needs HR, hiring, or corporate services, you can use 9cv9 hiring and recruitment services. Book a consultation slot here, or send over an email to [email protected].
If you find this article useful, why not share it with your hiring manager and C-level suite friends and also leave a nice comment below?
We, at the 9cv9 Research Team, strive to bring the latest and most meaningful data, guides, and statistics to your doorstep.
To get access to top-quality guides, click over to 9cv9 Blog.
People Also Ask
What are Large Language Models (LLMs)?
Large Language Models (LLMs) are advanced AI systems designed to understand and generate human-like text based on vast amounts of data.
How do LLMs work?
LLMs use deep learning algorithms to analyze and learn patterns from large datasets, allowing them to generate contextually relevant text.
What are the benefits of using LLMs?
LLMs enable tasks such as language translation, content generation, and conversational AI, enhancing productivity and efficiency across various industries.
What factors determine the quality of an LLM?
Key factors include model size, training data quality, architecture, and the efficiency of inference mechanisms.
How do I evaluate the performance of an LLM?
Performance is assessed based on metrics like fluency, coherence, accuracy, and the ability to generate contextually appropriate responses.
What are some popular LLMs in 2024?
Top LLMs include GPT-4, Claude 3, Mistral 7B, Gemma, Falcon 180B, and more, each offering unique features and capabilities.
What are multimodal LLMs?
Multimodal LLMs can process and generate text, images, audio, and video, enabling more comprehensive understanding and interaction.
How do I choose the right LLM for my needs?
Consider factors such as task requirements, model capabilities, computational resources, and ethical considerations when selecting an LLM.
Can I fine-tune an LLM for specific tasks?
Yes, many LLMs support fine-tuning on domain-specific data to improve performance for specific tasks or industries.
What are some ethical considerations when using LLMs?
Ethical concerns include bias in training data, potential misuse of generated content, privacy implications, and societal impact.
How do LLMs contribute to advancements in AI research?
LLMs serve as testbeds for exploring language understanding, generation, and reasoning, driving progress in AI research and development.
Are there any limitations to LLMs?
LLMs may struggle with understanding context, generating accurate responses in niche domains, and exhibiting biases present in training data.
How do LLMs handle multilingual tasks?
Many LLMs support multiple languages and can be fine-tuned on multilingual datasets to enhance language understanding and generation.
What role do LLMs play in natural language processing (NLP)?
LLMs are central to NLP tasks such as machine translation, sentiment analysis, text summarization, and question-answering systems.
Can LLMs be deployed in real-world applications?
Yes, LLMs are used in various real-world applications, including virtual assistants, content creation tools, chatbots, and customer service automation.
How do LLMs impact content creation?
LLMs empower content creators by automating tasks like generating articles, summarizing text, and providing creative suggestions.
What are some examples of successful LLM applications?
LLMs are used in virtual assistants like Siri, content recommendation systems, language translation services, and automated content generation tools.
How do LLMs contribute to personalized user experiences?
By analyzing user input and context, LLMs can generate personalized responses, recommendations, and suggestions tailored to individual preferences.
Are LLMs accessible for developers and researchers?
Yes, many LLMs are open-source or available through APIs, allowing developers and researchers to experiment, fine-tune, and integrate them into their projects.
How do LLMs impact the future of human-computer interaction?
LLMs pave the way for more natural and intuitive human-computer interactions, enabling seamless communication and collaboration between humans and machines.
What are some recent advancements in LLM technology?
Advancements include improvements in model architecture, training algorithms, efficiency, multimodal capabilities, and fine-tuning techniques.
How do LLMs address concerns about data privacy?
LLMs can be designed to prioritize user privacy by implementing techniques like differential privacy, data anonymization, and secure federated learning.
What role do LLMs play in education?
LLMs support educational initiatives by providing personalized tutoring, generating educational content, and facilitating language learning through interactive experiences.
Can LLMs assist in medical research and healthcare?
Yes, LLMs are used in medical research for tasks such as analyzing medical literature, diagnosing diseases, and personalizing treatment plans based on patient data.
How do LLMs contribute to the accessibility of information?
LLMs enable the creation of tools for text-to-speech conversion, summarization of complex documents, and translation of content into multiple languages, making information more accessible to diverse audiences.
Are there any potential risks associated with LLMs?
Risks include the spread of misinformation, amplification of biases present in training data, potential for malicious use, and ethical dilemmas surrounding AI-generated content.
How do LLMs support innovation in business and industry?
LLMs drive innovation by automating tasks, improving decision-making processes, enhancing customer experiences, and enabling the development of new products and services.
How can I stay updated on the latest developments in LLM technology?
Stay informed by following AI research publications, attending conferences and workshops, joining online communities, and exploring educational resources dedicated to LLMs and AI advancements.

")




{kind=link}